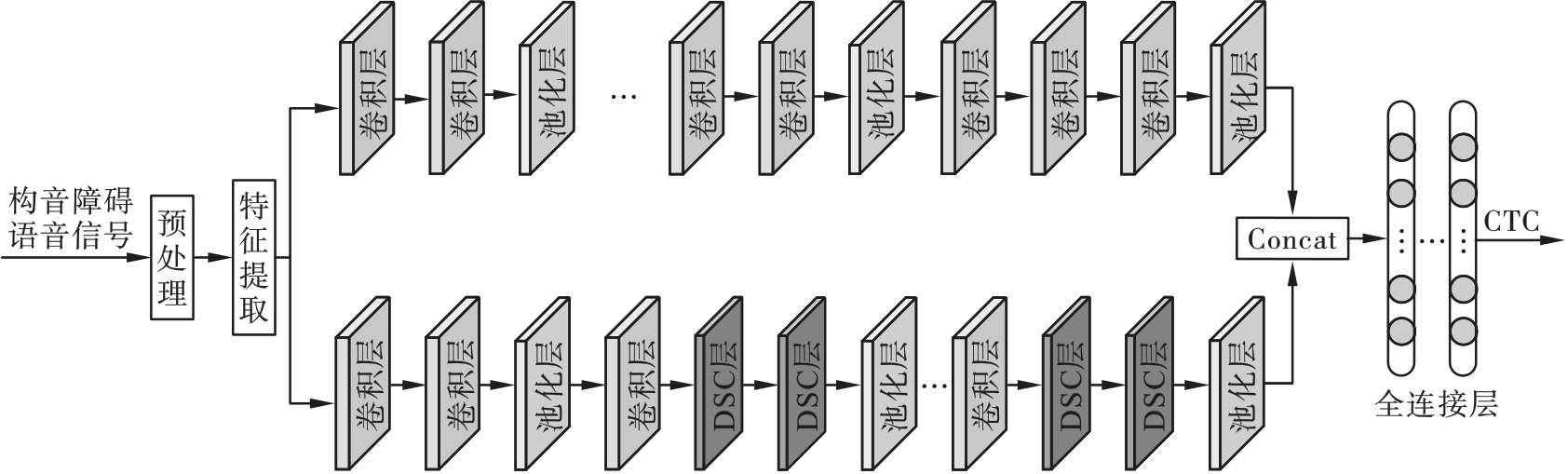
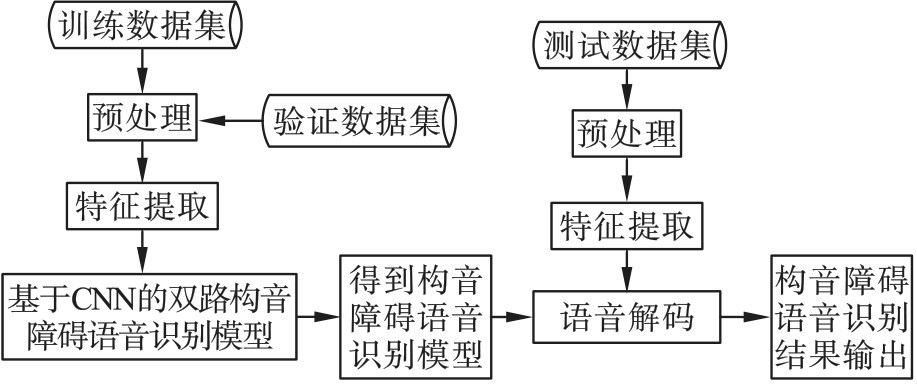
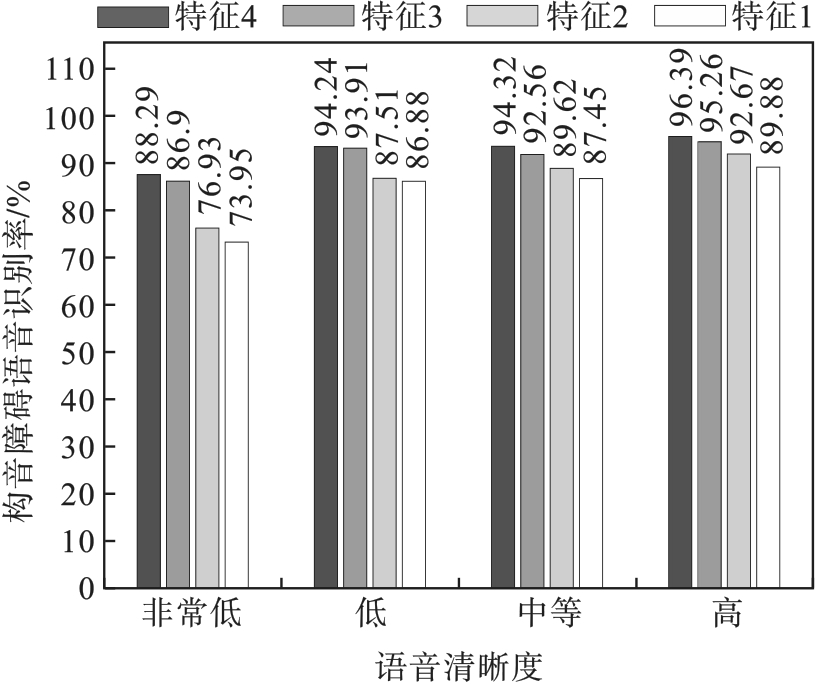
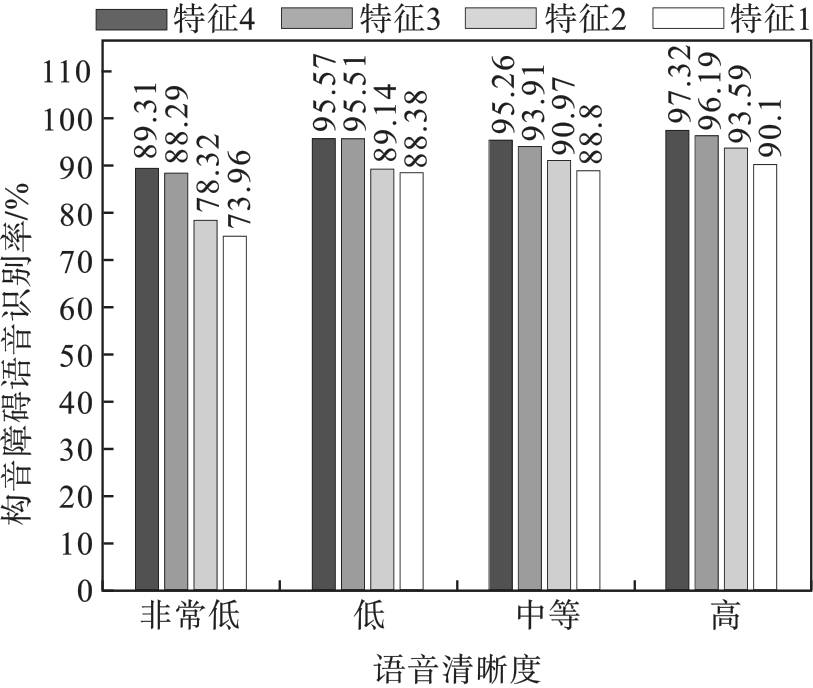
| 1 |
Mohammed S Y, Sid‑Ahmed S, Brahim‑Fares Z,et al.Improving dysarthric speech recognition using empirical mode decomposition and convolutional neural network[J].EURASIP Journal on Audio,Speech,and Music Processing,2020,2020(1):1-7.
|
| 2 |
Al‑Qatab B A, Mustafa M B.Classification of dysarthric speech according to the severity of impairment:an analysis of acoustic features[J].IEEE Access,2021(9):18183-18194.
|
| 3 |
Liu S, Hu S, Xie X,et al.Recent progress in the CUHK dysarthric speech recognition system[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2021,29(99):2267-2281.
|
| 4 |
Yue Z, Loweimi E, Christensen H,et al.Acoustic modelling from raw source and filter components for dysarthric speech recognition[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2022(30):2968-2980.
|
| 5 |
梁正友,黎雨星,孙宇,等.基于多特征组合的构音障碍语音识别[J].计算机工程与设计,2022,43(2):567-572.
|
|
Liang Zheng‑you, Li Yu‑xing, Sun Yu,et al.Speech recognition with dysarthria based on multi‑feature combination[J].Computer Engineering and Design,2022,43(2):567-572.
|
| 6 |
Jiao Y, Tu M, Berisha V,et al.Simulating dysarthric speech for training data augmentation in clinical speech applications[C]//2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Calgary Allcerta:IEEE,2018:6009-6013.
|
| 7 |
Yilmaz E, Mitra V, Sivaraman G,et al.Articulatory and bottleneck features for speaker‑independent ASR of dysarthric speech[J].Computer Speech & Language,2019,58:319-334.
|
| 8 |
Zaidi B F, Selouani S A, Boudraa M,et al.Deep neural network architectures for dysarthric speech analysis and recognition[J].Neural Computing and Applications,2021,33(15):9089-9108.
|
| 9 |
Mariya T A, Vijayalakshmi P, Nagarajan T.Data augmentation techniques for transfer learning‑based continuous dysarthric speech recognition[J].Circuits,Systems,and Signal Processing,2023,42(1):601-622.
|
| 10 |
李东,张雪英,段淑斐,等.结合语音融合特征和随机森林的构音障碍识别[J].西安电子科技大学学报,2018,45(3):149-155.
|
|
Li Dong, Zhang Xue‑ying, Duan Shu‑fei,et al.Articulation disorder recognition based on speech fusion features and random forest[J].Journal of Xidian University,2018,45(3):149-155.
|
| 11 |
吴丽丹.基于深度时序网络的多视图构音障碍语音识别[D].上海:华东师范大学,2021.
|
|
Wu Li‑dan.Multi‑view articulation disorder speech recognition based on deep temporal network[D].Shanghai:East China Normal University,2021.
|
| 12 |
王赵国,韦存海,彭雅妮,等.基于GFCC-SVM-RFE的电力设备声音特征提取方法[J].电力信息与通信技术,2022,20(9):34-42.
|
|
Wang Zhao‑guo, Wei Cun‑hai, Peng Ya‑ni,et al.Sound feature extraction method of Power Equipment based on GFCC‑SVM‑RFE[J].Electric Power Information and Communication Technology,2022,20(9):34-42.
|
| 13 |
Dragomiretskiy K, Zosso D.Variational mode decomposition[J].IEEE Transactions on Signal Processing,2014,62(3):531-544.
|
| 14 |
Fritsch J, Magimai‑Doss M.Utterance verification‑based dysarthric speech intelligibility assessment using phonetic posterior features[J].IEEE Signal Processing Letters,2021(28):224-228.
|
| 15 |
Shahamiri S R, Salim S.Artificial neural networks as speech recognisers for dysarthric speech:identifying the best‑performing set of MFCC parameters and studying a speaker‑independent approach[J].Advanced Engineering Informatics,2014,28(1):102-110.
|
| 16 |
Rajeswari N, Chandrakala S.Generative model‑driven feature learning for dysarthric speech recognition[J].Biocybernetics & Biomedical Engineering,2016,36(4):553-561.
|
| 17 |
Shahamiri S R.Speech vision:an end‑to‑end deep learning‑based dysarthric automatic speech recognition system[J].IEEE Transactions on Neural Systems and Rehabilitation Engineering,2021(29):852-861.
|
 ), 白静1, 张楠3, 赵建星1
), 白静1, 张楠3, 赵建星1