东北大学学报(自然科学版) ›› 2025, Vol. 46 ›› Issue (5): 37-45.DOI: 10.12068/j.issn.1005-3026.2025.20240015
刘旭泽1, 王慧颖2, 褚良宇3, 赵宇海1( )
)
收稿日期:2024-01-17
出版日期:2025-05-15
发布日期:2025-08-07
通讯作者:
赵宇海
作者简介:刘旭泽(1992—),男,辽宁盘锦人,东北大学博士研究生
基金资助:
Xu-ze LIU1, Hui-ying WANG2, Liang-yu CHU3, Yu-hai ZHAO1()
Received:2024-01-17
Online:2025-05-15
Published:2025-08-07
Contact:
Yu-hai ZHAO
摘要:
为了解决大数据挖掘中多重假设检验导致的假阳性问题,以及控制伪发现率(false discovery rate,FDR) 理论结果计算过程极其耗时的问题,针对理论FDR值的计算效率问题,提出了一种分布式假阳性控制算法DPFDR(distributed permutation testing-based false discovery rat, DPFDR).该算法首先基于条件频繁模式树(conditional frequent pattern tree,CFP)方法进行代表模式挖掘,利用代表模式对模式空间进行压缩.然后,根据代表模式对相应任务的工作量进行预估,按照工作量进行数据划分,并通过负载均衡策略将任务分配到各计算结点上.最后,通过合并、排序各结点的计算结果,获得有效的FDR假阳性控制阈值.真实数据集上的一系列实验结果表明,提出的DPFDR算法能极大提升FDR假阳性控制阈值的计算效率.
中图分类号:
刘旭泽, 王慧颖, 褚良宇, 赵宇海. 一种高效的分布式FDR假阳性控制算法[J]. 东北大学学报(自然科学版), 2025, 46(5): 37-45.
Xu-ze LIU, Hui-ying WANG, Liang-yu CHU, Yu-hai ZHAO. An Efficient Distributed False Positive Control Algorithm for FDR[J]. Journal of Northeastern University(Natural Science), 2025, 46(5): 37-45.
| 项目 | 不拒绝H0 | 拒绝H0 | 总计 |
|---|---|---|---|
| H0为真 | U | V | n0 |
| H0为假 | T | S | n-n0 |
| 总计 | n-R | R | n |
表1 多重假设检验结果
Table 1 Results of multiple hypothesis testing
| 项目 | 不拒绝H0 | 拒绝H0 | 总计 |
|---|---|---|---|
| H0为真 | U | V | n0 |
| H0为假 | T | S | n-n0 |
| 总计 | n-R | R | n |
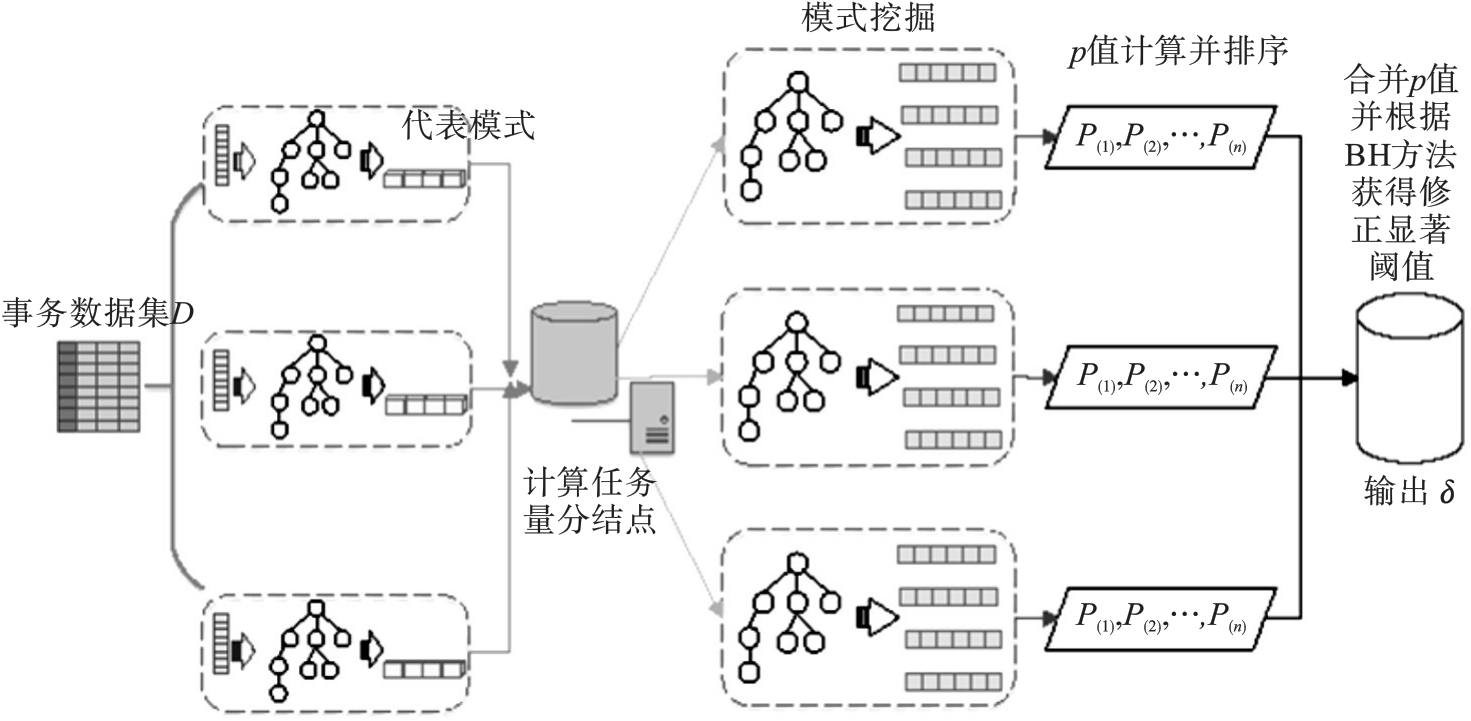
图1 FDR假阳性控制总体框架图
Fig.1 Overall framework of FDR false positive control
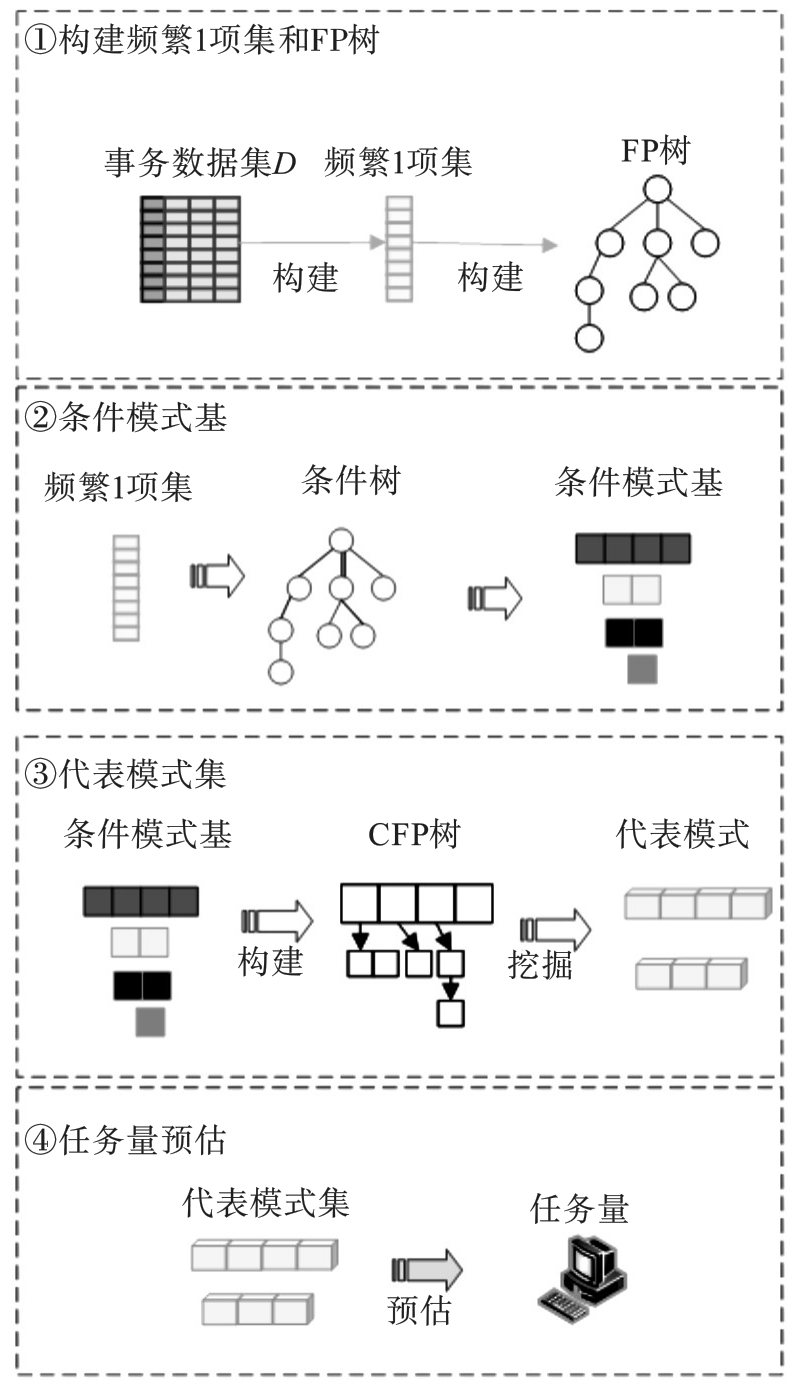
图2 任务量预估
Fig.2 Task volume estimation
| TID | 事务 |
|---|---|
| 1 | a,b,c,j |
| 2 | a,b,c,d,j |
| 3 | a,b,c |
| 4 | c,d,e,f |
| 5 | d,e,f,j |
表2 事务数据集
Table 2 Transaction data sets
| TID | 事务 |
|---|---|
| 1 | a,b,c,j |
| 2 | a,b,c,d,j |
| 3 | a,b,c |
| 4 | c,d,e,f |
| 5 | d,e,f,j |
| ID | 模式 | 支持度 |
|---|---|---|
| 1 | a | 3 |
| 2 | b,c | 3 |
| 3 | a,c | 3 |
| 4 | a,b,c | 3 |
| 5 | a,b,c,d | 1 |
表3 部分频繁模式集
Table 3 Partially frequent patterns sets
| ID | 模式 | 支持度 |
|---|---|---|
| 1 | a | 3 |
| 2 | b,c | 3 |
| 3 | a,c | 3 |
| 4 | a,b,c | 3 |
| 5 | a,b,c,d | 1 |
| n项集 | 所有模式(min_support=2) |
|---|---|
| 1 | e:2,f:2,a:3,b:3,d:3,j:3,c:4 |
| 2 | ef:2,ed:2,fd:2,ab:3,ac:3,aj:2,bc:3,bj:2,dc:2,dj:2,jc:2 |
| 3 | abc:3,abj:2,acj:2,bcj:2,efd:2 |
| 4 | abcj:2 |
表4 所有模式
Table 4 All patterns
| n项集 | 所有模式(min_support=2) |
|---|---|
| 1 | e:2,f:2,a:3,b:3,d:3,j:3,c:4 |
| 2 | ef:2,ed:2,fd:2,ab:3,ac:3,aj:2,bc:3,bj:2,dc:2,dj:2,jc:2 |
| 3 | abc:3,abj:2,acj:2,bcj:2,efd:2 |
| 4 | abcj:2 |
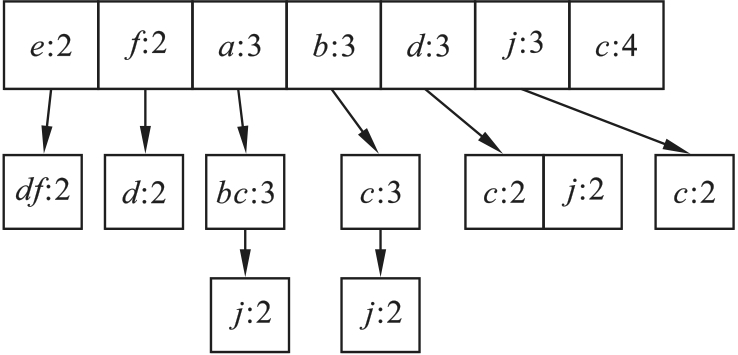
图3 CFP树结构
Fig. 3 CFP tree structure
| 数据集 | |D| | 项目数 | 事务平均长度 | n/n1 | 事务长度最大值 | 事务长度最小值 |
|---|---|---|---|---|---|---|
| A9a(L) | 32,561 | 247 | 13.9 | 4.17 | 14 | 11 |
| Bms-Web2(U) | 77,158 | 330,285 | 4.59 | 25 | 66 | 1 |
| Breast-Cancer(L) | 12,773 | 1,129 | 6.7 | 11.11 | 53 | 1 |
| Codrna(L) | 271,617 | 16 | 8 | 3.03 | 8 | 8 |
| Ijcnn1(L) | 91,701 | 44 | 13 | 10 | 13 | 13 |
| T10I4D100K_new(U) | 100,000 | 870 | 10.1 | 12.5 | 20 | 1 |
表5 实验数据集
Table 5 Experimental data sets
| 数据集 | |D| | 项目数 | 事务平均长度 | n/n1 | 事务长度最大值 | 事务长度最小值 |
|---|---|---|---|---|---|---|
| A9a(L) | 32,561 | 247 | 13.9 | 4.17 | 14 | 11 |
| Bms-Web2(U) | 77,158 | 330,285 | 4.59 | 25 | 66 | 1 |
| Breast-Cancer(L) | 12,773 | 1,129 | 6.7 | 11.11 | 53 | 1 |
| Codrna(L) | 271,617 | 16 | 8 | 3.03 | 8 | 8 |
| Ijcnn1(L) | 91,701 | 44 | 13 | 10 | 13 | 13 |
| T10I4D100K_new(U) | 100,000 | 870 | 10.1 | 12.5 | 20 | 1 |
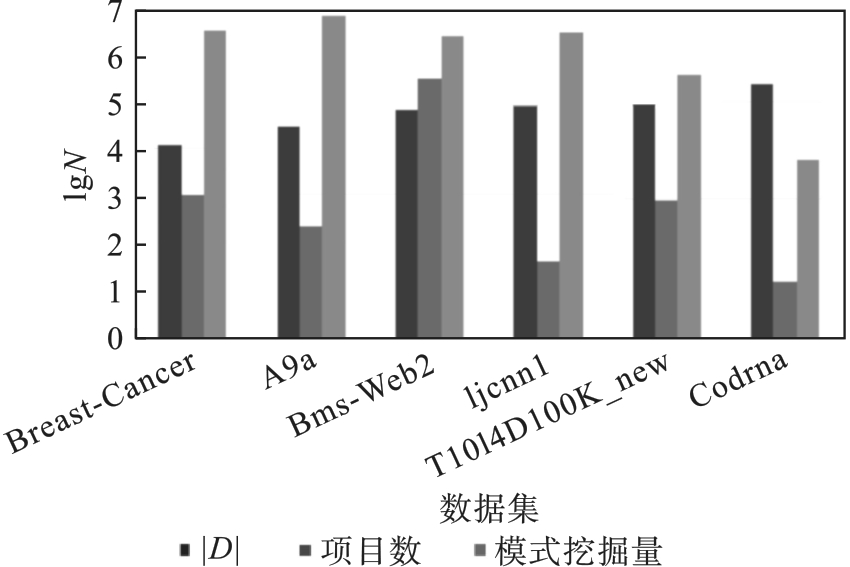
图4 事务数项目数和模式挖掘数
Fig.4 Number of transactions number of items and number of pattern mining
| 数据集 | FDR |
|---|---|
| A9a | 0.0499 |
| Bms-Web2 | 0.0496 |
| Breast-Cancer | 0.0421 |
| Codrna | 0.0497 |
| Ijcnn1 | 0.0497 |
| T10I4D100K_new | 0.0491 |
表6 不同数据集的FDR控制效果
Table 6 FDR control effect of different data sets
| 数据集 | FDR |
|---|---|
| A9a | 0.0499 |
| Bms-Web2 | 0.0496 |
| Breast-Cancer | 0.0421 |
| Codrna | 0.0497 |
| Ijcnn1 | 0.0497 |
| T10I4D100K_new | 0.0491 |
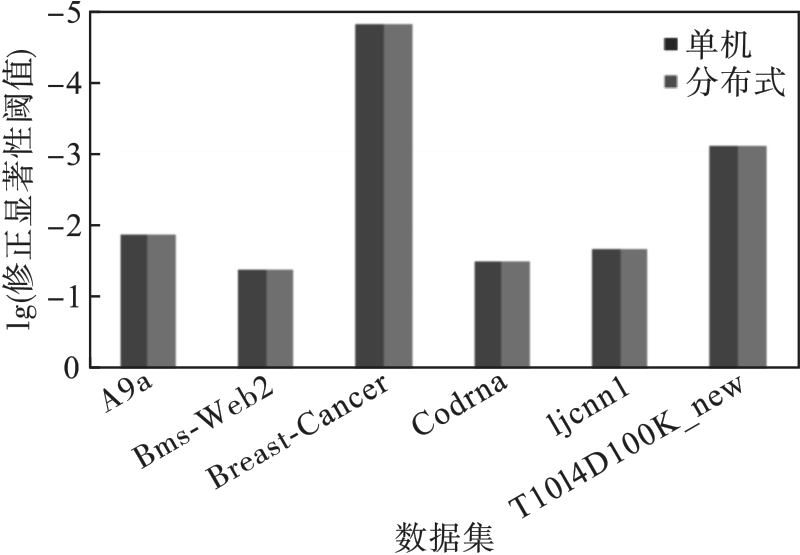
图5 FDR不同数据集的修正显著性阈值
Fig.5 Modified significance thresholds for different data sets of FDR
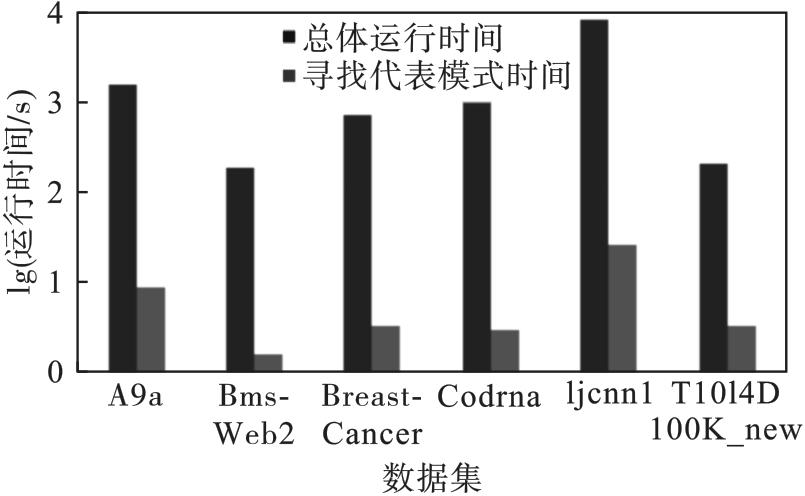
图6 寻找代表模式运行时间
Fig.6 Find representative mode running time
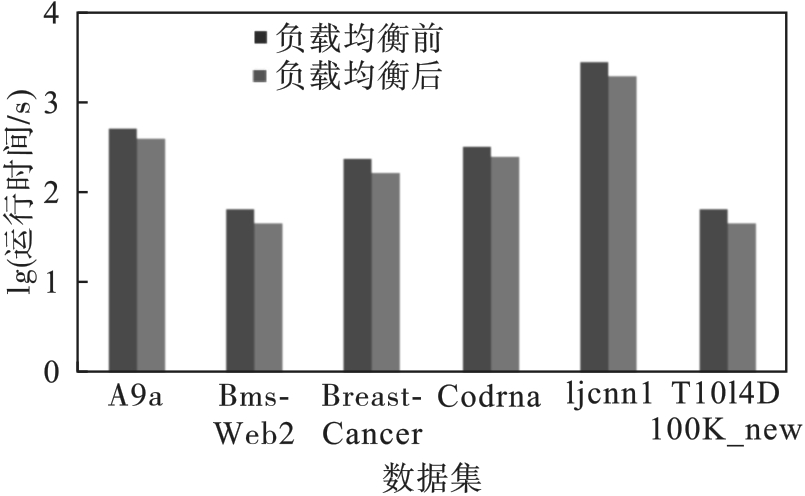
图7 负载均衡前后时间对比
Fig.7 Time comparison before and after load balancing
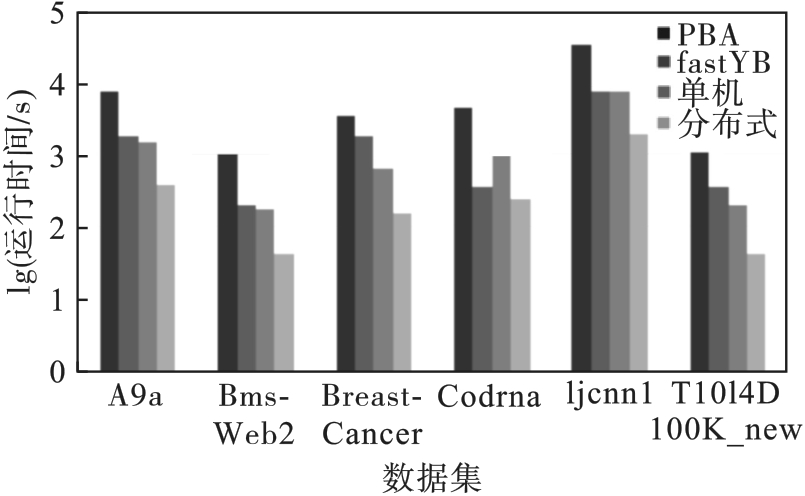
图8 分布式FDR假阳性控制算法与现有算法的运行时间
Fig.8 Running time of distributed FDR false positive control algorithm and existing algorithms
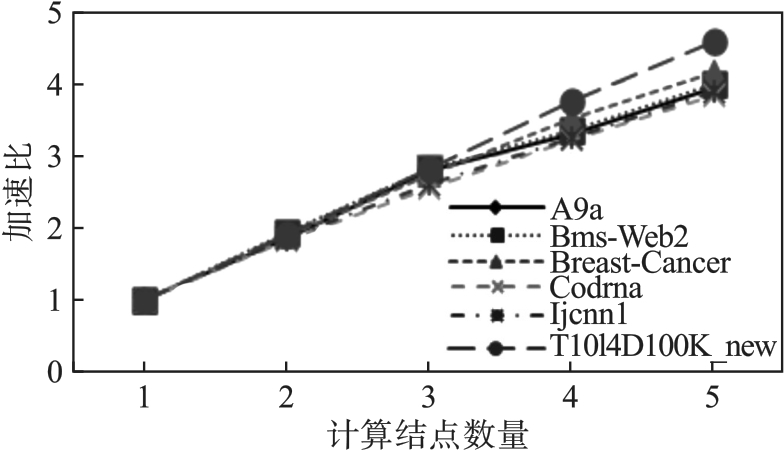
图9 分布式算法加速比
Fig.9 Distributed algorithm speed ratio
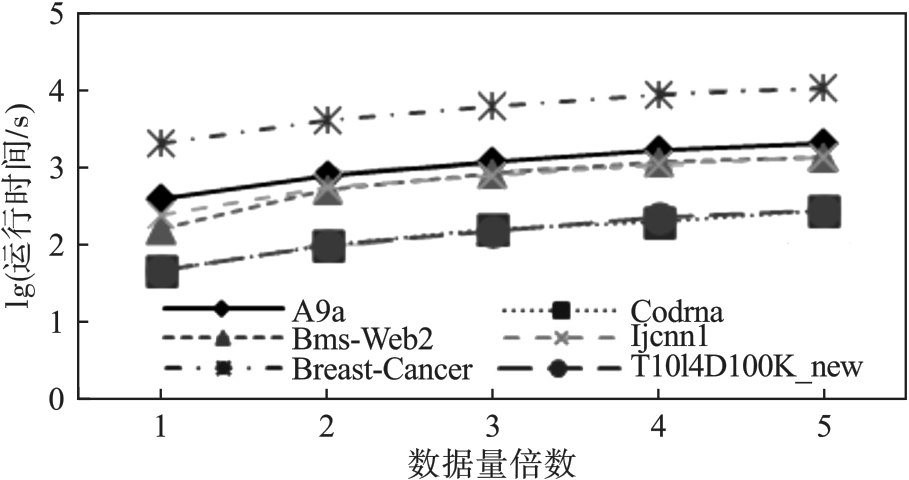
图10 分布式算法可伸缩性
Fig.10 Distributed algorithm scalability
| [1] | Erdogmus H. Bayesian hypothesis testing illustrated: an introduction for software engineering researchers[J]. ACM Computing Surveys, 2022, 55(6): 1-28. |
| [2] | Kelter R. Power analysis and type I and type II error rates of Bayesian nonparametric two-sample tests for location-shifts based on the Bayes factor under Cauchy priors[J]. Computational Statistics & Data Analysis, 2022, 165: 107326. |
| [3] | de Araújo Silva A, Gouvêa M A. Study on the effect of sample size on type I error, in the first, second and first-two digits Excess tests[J]. International Journal of Accounting Information Systems, 2023, 48: 100599. |
| [4] | Liu H P, Zhang J V, Wang D, et al. Extended endocrine therapy in breast cancer: a basket of length-constraint feature selection metaheuristics to balance type I against type II errors[J]. Journal of Biomedical Informatics, 2022, 131: 104112. |
| [5] | Sharma V S, Afthanorhan A, Barwar N C, et al. A dynamic repository approach for small file management with fast access time on Hadoop cluster: Hash based extended Hadoop archive[J]. IEEE Access, 2022, 10: 36856-36867. |
| [6] | Luo C, Cao Q, Li T R, et al. MapReduce accelerated attribute reduction based on neighborhood entropy with Apache Spark[J]. Expert Systems with Applications, 2023, 211: 118554. |
| [7] | Llinares-López F, Sugiyama M, Papaxanthos L, et al. Fast and memory-efficient significant pattern mining via permutation testing[C]// Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney, 2015: 725-734. |
| [8] | Dey M, Bhandari S K. FWER goes to zero for correlated normal[J]. Statistics & Probability Letters, 2023, 193: 109700. |
| [9] | Terada A, Sese J. Bonferroni correction hides significant motif combinations[C]// 13th IEEE International Conference on BioInformatics and BioEngineering. Chania,2013: 1-4. |
| [10] | Holm S. A simple sequentially rejective multiple test procedure[J]. Scandinavian Journal of Statistics, 1979, 6(2): 65-70. |
| [11] | Simes R J. An improved Bonferroni procedure for multiple tests of significance[J]. Biometrika, 1986, 73(3): 751-754. |
| [12] | Hochberg Y. A sharper Bonferroni procedure for multiple tests of significance[J]. Biometrika, 1988, 75(4): 800-802. |
| [13] | Chaubey Y P, Westfall P H, Young S S. Resampling-based multiple testing: examples and methods for p-value adjustment[J]. Technometrics, 1993, 35(4): 450. |
| [14] | Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing[J]. Journal of the Royal Statistical Society: Series B (Methodological), 1995, 57(1): 289-300. |
| [15] | Nawaz M S, Azam M, Aslam M. An efficient double exponentially weighted moving average Benjamini-Hochberg control chart to control false discovery rate[J]. Quality and Reliability Engineering International, 2019, 35(8): 2677-2686. |
| [16] | Cui J F, Wang G H, Zou C L, et al. Change-point testing for parallel data sets with FDR control[J]. Computational Statistics & Data Analysis, 2023, 182: 107705. |
| [17] | Liu G M, Zhang H J, Wong L S. Controlling false positives in association rule mining[J]. Proceedings of the VLDB Endowment, 2011, 5(2): 145-156. |
| [18] | Pellizzoni P, Borgwardt K. FASM and FAST-YB: significant pattern mining with false discovery rate control[C]// 2023 IEEE International Conference on Data Mining (ICDM). Shanghai,2023: 1265-1270. |
| [19] | Sidák Z. On multivariate normal probabilities of rectangles: their dependence on correlations[J]. The Annals of Mathematical Statistics, 1968, 39(5): 1425-1434. |
| [20] | Bestgen Y. Using Fisher’s exact test to evaluate association measures for N-grams[EB/OL]. (2021-04-29) [2023-12-29]. . |
| [21] | Liu G M, Zhang H J, Wong L S. A flexible approach to finding representative pattern sets[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 26(7): 1562-1574. |
| [22] | Liu G M, Lu H J, Yu J X. CFP-tree: a compact disk-based structure for storing and querying frequent itemsets[J]. Information Systems, 2007, 32(2): 295-319. |
| [23] | 季策,王金芝,耿蓉. 基于Dice系数的弱选择回溯匹配追踪算法[J].东北大学学报(自然科学版), 2021,42(2): 189-195. |
| Ji Ce, Wang Jin-zhi, Geng Rong. Weak-selection backtracking matching pursuit algorithm based on Dice coefficient[J]. Journal of Northeastern University (Natural Science), 2021,42(2): 189-195. |
| [1] | 刘馨, 张卫军, 石泉, 周乐. 基于数据挖掘与清洗的高炉操作参数优化[J]. 东北大学学报:自然科学版, 2020, 41(8): 1153-1160. |
| [2] | 韩东红, 王坤, 邵崇雷, 马畅. 一种面向不确定数据流的聚类算法[J]. 东北大学学报:自然科学版, 2016, 37(12): 1677-1682. |
| [3] | 张明卫, 张小旭, 刘莹, 韩春燕. 面向主属性值的类标特征分析[J]. 东北大学学报:自然科学版, 2016, 37(10): 1388-1392. |
| [4] | 张天瑞, 于天彪, 赵海峰, 王宛山. 数据挖掘技术在全断面掘进机故障诊断中的应用[J]. 东北大学学报:自然科学版, 2015, 36(4): 527-532. |
| [5] | 赵宇海, 印莹, 王雪. 一种基于图压缩的重叠社区发现算法[J]. 东北大学学报:自然科学版, 2015, 36(11): 1543-1547. |
| [6] | 宫俊;董俊龙;梁茂新;唐加福;. 基于关联规则的广义药对最适合病证的挖掘方法[J]. 东北大学学报(自然科学版), 2011, 32(8): 1097-1100. |
| [7] | 王恩泽;乔建忠;林树宽;. 一种基于超边际分析的分布式计算资源分配方法[J]. 东北大学学报(自然科学版), 2011, 32(2): 219-222+231. |
| [8] | 张明卫;王波;张斌;朱志良;. 基于相关系数的加权朴素贝叶斯分类算法[J]. 东北大学学报(自然科学版), 2008, 29(7): 952-955. |
| [9] | 魏伟杰;张斌;王波;张明卫;. 一种用于数据挖掘算法的数据生成方法[J]. 东北大学学报(自然科学版), 2008, 29(3): 328-331. |
| [10] | 于勇前;赵相国;陈衡岳;王国仁;. 基于引力概念的聚类质量评估算法[J]. 东北大学学报(自然科学版), 2007, 28(8): 1109-1112. |
| [11] | 丁敬国;胡贤磊;焦景民;刘相华;. 基于粗糙集的关联规则数据挖掘在层流冷却中的应用[J]. 东北大学学报(自然科学版), 2007, 28(11): 1583-1585+1598. |
| [12] | 吴成东;许可;韩中华;裴涛;. 基于粗糙集和决策树的数据挖掘方法[J]. 东北大学学报(自然科学版), 2006, 27(5): 481-484. |
| [13] | 焦明海;姜慧研;唐加福;. 一种基于聚合链的改进FP-Growth算法[J]. 东北大学学报(自然科学版), 2006, 27(2): 153-156. |
| [14] | 赵晓煜;黄小原;. 基于数据挖掘的客户价值预测方法[J]. 东北大学学报(自然科学版), 2006, 27(12): 1393-1396. |
| [15] | 董晓梅;于戈. 入侵报警模式挖掘分析算法研究[J]. 东北大学学报(自然科学版), 2005, 26(11): 27-30. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||