东北大学学报(自然科学版) ›› 2025, Vol. 46 ›› Issue (1): 1-8.DOI: 10.12068/j.issn.1005-3026.2025.20230204
• 信息与控制 •
万应才, 房立金, 赵乾坤
收稿日期:2023-07-17
出版日期:2025-01-15
发布日期:2025-03-25
作者简介:万应才(1990—),男,甘肃靖远人,东北大学博士研究生基金资助:Ying-cai WAN, Li-jin FANG, Qian-kun ZHAO
Received:2023-07-17
Online:2025-01-15
Published:2025-03-25
摘要:
玻璃和镜子等物体因缺乏明显纹理和形状,使得传统语义分割方法难以有效识别,影响视觉任务准确性.为了解决这个问题提出了一种基于Transformer的RGBD跨模态融合方法,用于玻璃类似物的分割.该方法采用Transformer网络,通过跨模态融合模块提取RGB和深度特征的自注意力,并利用多层注意力机制(MLP)整合RGBD特征,实现3种注意力特征的融合.RGB和深度特征被反馈到各自分支,以增强网络的特征提取能力.最终,语义分割解码器结合4个阶段的融合特征输出玻璃类似物的分割结果.结果表明,本文方法与EBLNet方法相比在GDD,Trans10k和MSD数据集上的交并比分别提高1.64%,2.26%,7.38%,与PDNet方法比较在RGBD-Mirror数据集上交并比提高了9.49%,验证了其有效性.
中图分类号:
万应才, 房立金, 赵乾坤. 基于跨模态融合的玻璃类似物分割方法[J]. 东北大学学报(自然科学版), 2025, 46(1): 1-8.
Ying-cai WAN, Li-jin FANG, Qian-kun ZHAO. Segmentation Method for Glass-like Object Based on Cross-Modal Fusion[J]. Journal of Northeastern University(Natural Science), 2025, 46(1): 1-8.
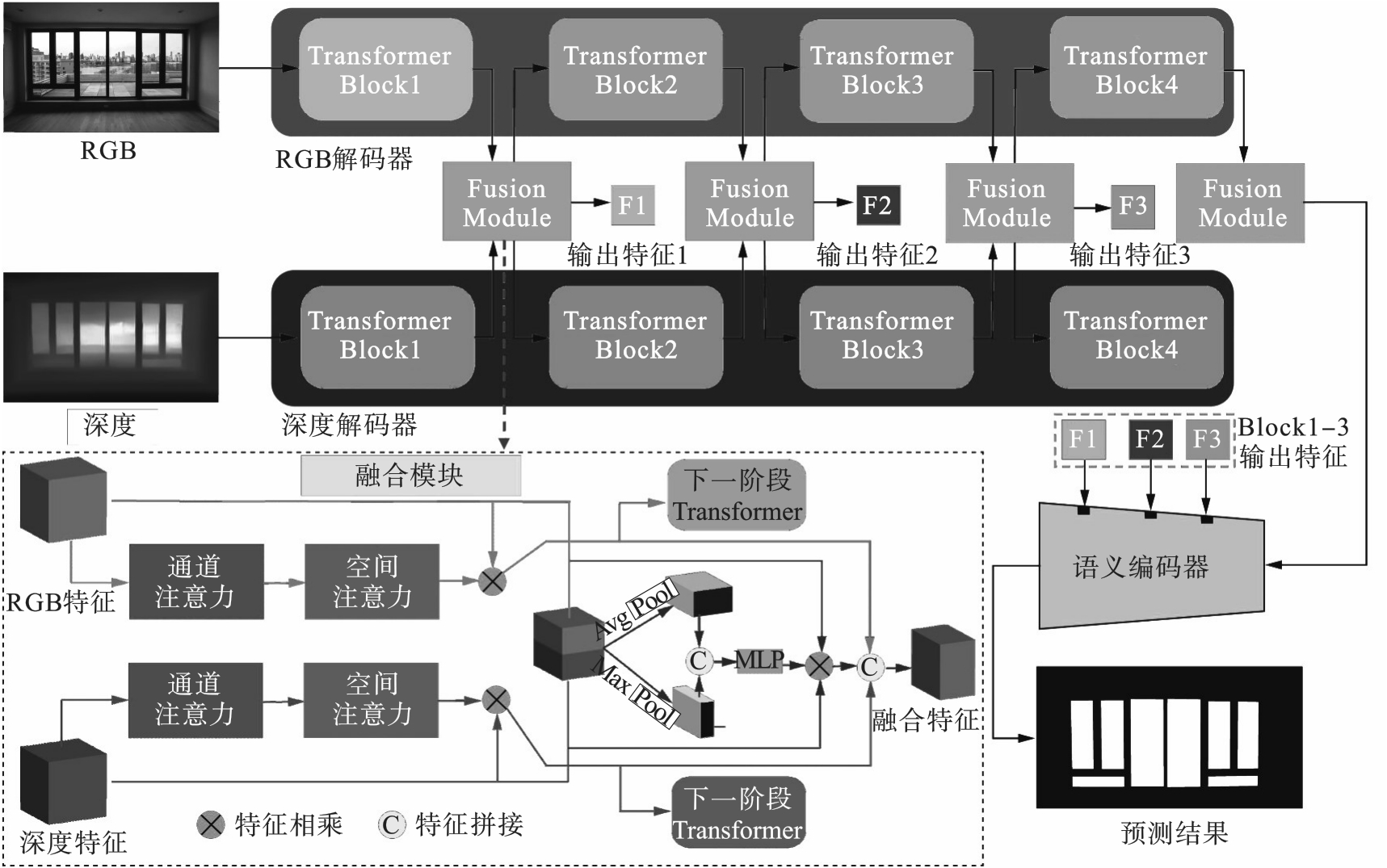
图1 RGBD跨模态融合玻璃类似物分割框图
Fig.1 The framework of RGBD cross‑modal fusion for glass‑like object segmentation
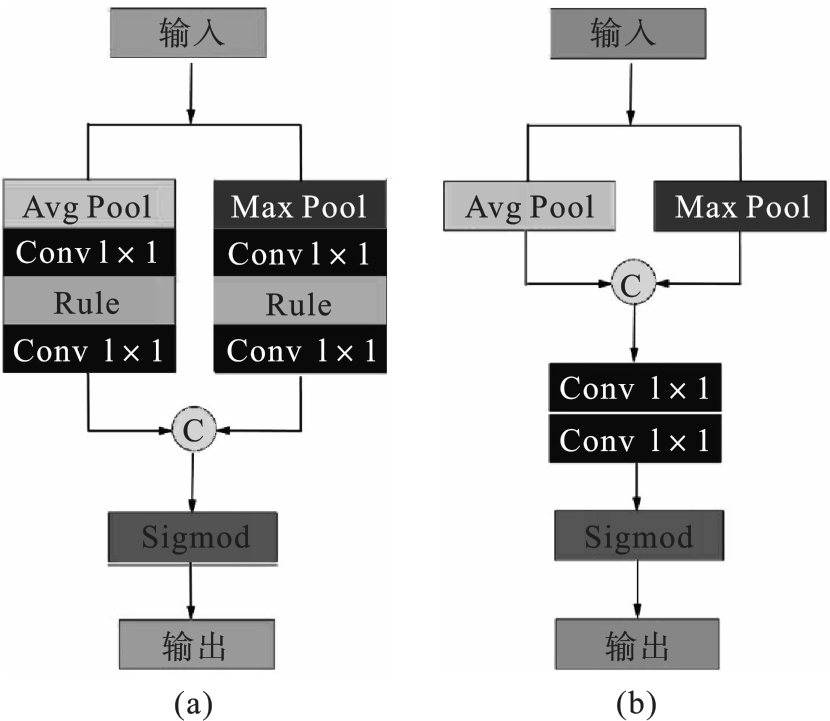
图2 玻璃类似物通道注意力与空间注意力特征提取结构(a)—通道注意力; (b)—空间注意力.
Fig.2 Structure diagram of channel attention and space attention feature extraction of GLO
| 方法 | 骨干网络 | GDD | Trans10k | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ICNet[ | ResNet-50 | 69.59 | 0.747 | 0.164 | 16.10 | 74.94 | 0.784 | 0.110 | 10.92 |
| DeepLabv3+[ | ResNet-50 | 69.95 | 0.767 | 0.147 | 15.49 | 51.52 | 0.602 | 0.229 | 23.80 |
| MINet-R[ | ResNet-50 | 82.03 | 0.847 | 0.092 | 8.55 | 85.88 | 0.881 | 0.060 | 6.03 |
| ITSD[ | ResNet-50 | 83.72 | 0.862 | 0.087 | 7.77 | 85.44 | 0.871 | 0.063 | 6.26 |
| MirrorNet[ | ResNeXt-101 | 85.07 | 0.866 | 0.083 | 7.67 | 88.30 | 0.907 | 0.047 | 4.95 |
| TransLab[ | ResNet-50 | 81.64 | 0.849 | 0.097 | 9.70 | 87.10 | 0.897 | 0.051 | 5.44 |
| GDNet[ | ResNeXt-101 | 87.63 | 0.898 | 0.063 | 5.62 | 88.68 | 0.907 | 0.046 | 4.72 |
| GSD[ | ResNeXt-101 | 88.07 | 0.932 | 0.059 | 5.71 | 89.16 | 0.937 | 0.043 | 4.50 |
| PGSNet[ | ResNeXt-101 | 87.81 | 0.901 | 0.062 | 5.56 | 89.79 | 0.917 | 0.042 | 4.39 |
| EBLNet[ | ResNeXt-101 | 88.16 | 0.939 | 0.059 | 5.58 | 90.28 | 0.947 | 0.048 | 4.14 |
| 本文方法 | Swin-s | 89.61 | 0.942 | 0.060 | 5.02 | 92.32 | 0.949 | 0.035 | 2.98 |
表1 在 GDD 和 Trans10k 数据集上与其他方法进行定量比较
Table 1 Quantitative comparison with other methods on the GDD and Trans10k datasets.
| 方法 | 骨干网络 | GDD | Trans10k | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ICNet[ | ResNet-50 | 69.59 | 0.747 | 0.164 | 16.10 | 74.94 | 0.784 | 0.110 | 10.92 |
| DeepLabv3+[ | ResNet-50 | 69.95 | 0.767 | 0.147 | 15.49 | 51.52 | 0.602 | 0.229 | 23.80 |
| MINet-R[ | ResNet-50 | 82.03 | 0.847 | 0.092 | 8.55 | 85.88 | 0.881 | 0.060 | 6.03 |
| ITSD[ | ResNet-50 | 83.72 | 0.862 | 0.087 | 7.77 | 85.44 | 0.871 | 0.063 | 6.26 |
| MirrorNet[ | ResNeXt-101 | 85.07 | 0.866 | 0.083 | 7.67 | 88.30 | 0.907 | 0.047 | 4.95 |
| TransLab[ | ResNet-50 | 81.64 | 0.849 | 0.097 | 9.70 | 87.10 | 0.897 | 0.051 | 5.44 |
| GDNet[ | ResNeXt-101 | 87.63 | 0.898 | 0.063 | 5.62 | 88.68 | 0.907 | 0.046 | 4.72 |
| GSD[ | ResNeXt-101 | 88.07 | 0.932 | 0.059 | 5.71 | 89.16 | 0.937 | 0.043 | 4.50 |
| PGSNet[ | ResNeXt-101 | 87.81 | 0.901 | 0.062 | 5.56 | 89.79 | 0.917 | 0.042 | 4.39 |
| EBLNet[ | ResNeXt-101 | 88.16 | 0.939 | 0.059 | 5.58 | 90.28 | 0.947 | 0.048 | 4.14 |
| 本文方法 | Swin-s | 89.61 | 0.942 | 0.060 | 5.02 | 92.32 | 0.949 | 0.035 | 2.98 |
| 方法 | ||||
|---|---|---|---|---|
| ICNet[ | 57.25 | 0.710 | 0.124 | 18.75 |
| DeepLabv3+[ | 78.81 | 0.872 | 0.054 | 8.95 |
| MirrorNet[ | 78.95 | 0.857 | 0.065 | 6.39 |
| EBLNet[ | 80.33 | 0.883 | 0.049 | 8.63 |
| 本文方法 | 86.26 | 0.909 | 0.045 | 8.03 |
表2 在MSD数据集上与其他方法进行定量比较 (on the MSD dataset)
Table 2 Quantitative comparison with other methods
| 方法 | ||||
|---|---|---|---|---|
| ICNet[ | 57.25 | 0.710 | 0.124 | 18.75 |
| DeepLabv3+[ | 78.81 | 0.872 | 0.054 | 8.95 |
| MirrorNet[ | 78.95 | 0.857 | 0.065 | 6.39 |
| EBLNet[ | 80.33 | 0.883 | 0.049 | 8.63 |
| 本文方法 | 86.26 | 0.909 | 0.045 | 8.03 |
| 方法 | ||||
|---|---|---|---|---|
| F3Net[ | 65.15 | 0.707 | 0.069 | 14.25 |
| MirrorNet[ | 68.37 | 0.723 | 0.062 | 8.66 |
| PMD[ | 72.27 | 0.775 | 0.054 | 10.71 |
| PDNet[ | 77.77 | 0.825 | 0.042 | 7.77 |
| 本文方法 | 85.15 | 0.922 | 0.037 | 6.13 |
表3 在RGBD-Mirror数据集上与其他方法进行定量比较
Table 3 Quantitative comparison with other methods on the RGBD-Mirror dataset
| 方法 | ||||
|---|---|---|---|---|
| F3Net[ | 65.15 | 0.707 | 0.069 | 14.25 |
| MirrorNet[ | 68.37 | 0.723 | 0.062 | 8.66 |
| PMD[ | 72.27 | 0.775 | 0.054 | 10.71 |
| PDNet[ | 77.77 | 0.825 | 0.042 | 7.77 |
| 本文方法 | 85.15 | 0.922 | 0.037 | 6.13 |
| 方法 | ||||
|---|---|---|---|---|
PDNet[ PDNet(网络估计深度) | 77.77 | 0.825 | 0.042 | 7.77 |
| 78.58 | 0.849 | 0.041 | 7.01 | |
| 本文方法(相机采集深度) | 84.15 | 0.908 | 0.042 | 6.50 |
| 本文方法(网络估计深度) | 85.15 | 0.922 | 0.037 | 6.13 |
表5 不同类型深度消融实验结果 (depth ablation)
Table 5 Experimental results of different types of
| 方法 | ||||
|---|---|---|---|---|
PDNet[ PDNet(网络估计深度) | 77.77 | 0.825 | 0.042 | 7.77 |
| 78.58 | 0.849 | 0.041 | 7.01 | |
| 本文方法(相机采集深度) | 84.15 | 0.908 | 0.042 | 6.50 |
| 本文方法(网络估计深度) | 85.15 | 0.922 | 0.037 | 6.13 |

图3 注意力分布可视化图(a)—原图像; (b)—RGB输入; (c)—RGB+深度;(d)—RGB+深度+融合模块.
Fig.3 Visualization of attention distribution
| 第1阶段 | 第2阶段 | 第3阶段 | 第4阶段 | |
|---|---|---|---|---|
| | 87.71 | |||
| | 87.31 | |||
| | 87.29 | |||
| | 87.89 | |||
| | | 88.69 | ||
| | | | 89.48 | |
| | | | | 89.61 |
表7 不同融合阶段平均交并比指标对比
Table7 Results of mean intersection‑over‑union ratio at different fusion stages
| 第1阶段 | 第2阶段 | 第3阶段 | 第4阶段 | |
|---|---|---|---|---|
| | 87.71 | |||
| | 87.31 | |||
| | 87.29 | |||
| | 87.89 | |||
| | | 88.69 | ||
| | | | 89.48 | |
| | | | | 89.61 |

图4 真实场景玻璃类似物实验结果(a)—实物; (b)—分割结果.
Fig.4 Results of glass‑like objects in real scenes

图5 深度恢复过程(a)—输入图像; (b)—真实标签; (c)—深度图;(d)—玻璃区域分割结果; (e)—玻璃边界估计结果;(f)—调整后深度图.
Fig.5 The process of depth recovery
| 1 | Zhao H S, Qi X J, Shen X Y,et al.ICNet for real‑time semantic segmentation on high‑resolution images[C]//Proceedings of the European Conference on Computer Vision (ECCV 2018).Munich:Springer International Publishing,2018:418‑434. |
| 2 | Wang D Q, Zhang T, Süsstrunk S.NEMTO:neural environment matting for novel view and relighting synthesis of transparent objects[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV).Paris:IEEE,2023:317-327. |
| 3 | 王璐,王帅,张国峰,等.基于语义分割注意力与可见区域预测的行人检测方法[J].东北大学学报(自然科学版),2021,42(9):1261-1267. |
| Wang Lu, Wang Shuai, Zhang Guo‑feng,et al. Pedestrian detection based on semantic segmentation attention and visible region prediction[J].Journal of Northeastern University (Natural Science ),2021,42(9):1261-1267. | |
| 4 | 张之敏,乔建忠,林树宽,等.一种基于深度网络的视图重建方法[J].东北大学学报(自然科学版),2020,41(8):1065-1069. |
| Zhang Zhi‑min, Qiao Jian‑zhong, Lin Shu‑kuan,et al.A view reconstruction method based on deep network[J].Journal of Northeastern University (Natural Science),2020,41(8):1065-1069. | |
| 5 | Wang Z Y, Li Y C, Cheng X N,et al.Key points trajectory and multi‑level depth distinction based refinement for video mirror and glass segmentation[J].Multimedia Tools and Applications,2024,83(39):86513-86535. |
| 6 | Yang X, Mei H Y, Xu K,et al.Where is my mirror?[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2019:8808-8817. |
| 7 | Lin J Y, He Z B, Lau R W H.Rich context aggregation with reflection prior for glass surface detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:13410-13419. |
| 8 | Lin J Y, Wang G D, Lau R W H.Progressive mirror detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:3694-3702. |
| 9 | Mei H Y, Yang X, Wang Y,et al.Don’t hit me!glass detection in real‑world scenes[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:3684-3693. |
| 10 | He H, Li X T, Cheng G L,et al.Enhanced boundary learning for glass‑like object segmentation[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:15839-15848. |
| 11 | Mei H Y, Dong B, Dong W,et al.Depth‑aware mirror segmentation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:3043-3052. |
| 12 | Chang Q L, Liao H H, Meng X F,et al.PanoGlassNet:glass detection with panoramic RGB and intensity images[J].IEEE Transactions on Instrumentation and Measurement,2024,73:5019015. |
| 13 | Liu Z, Lin Y T, Cao Y,et al.Swin transformer:hierarchical vision transformer using shifted windows[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:9992-10002. |
| 14 | Yin W, Zhang J M, Wang O,et al.Learning to recover 3D scene shape from a single image[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:204-213. |
| 15 | Taud H, Mas J F.Multilayer perceptron (MLP)[M]//Cámacho O M T,Paegelow M,Mas J F,et al.Geomatic Approaches for Modeling Land Change Scenarios.Cham:Springer,2018:451-455. |
| 16 | Zhao H S, Shi J P, Qi X J,et al.Pyramid scene parsing network[C]//2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6230-6239. |
| 17 | Deng J J, Pan Y W, Yao T,et al.MINet:meta‑learning instance identifiers for video object detection[J].IEEE Transactions on Image Processing,2021,30:6879-6891. |
| 18 | Zhou H J, Xie X H, Lai J H,et al.Interactive two‑stream decoder for accurate and fast saliency detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:9138-9147. |
| 19 | Xie E Z, Wang W J, Wang W H,et al.Segmenting transparent objects in the wild[C]//Computer Vision and Pattern Recognition.Cham:Springer International Publishing,2020:696-711. |
| 20 | Wei J, Wang S H, Huang Q M.F3Net:fusion,feedback and focus for salient object detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence.New York:IEEE,2020:12321-12328. |
| [1] | 刘炎, 卜齐杰, 赵红晨, 郭鑫. 基于多源异构信息的浮选过程运行状态评价[J]. 东北大学学报(自然科学版), 2024, 45(9): 1217-1226. |
| [2] | 刘伟嵬, 邱佳鹤, 胡光大, 刘泽远. 基于改进YOLOv5的退役轴类零件表面损伤检测方法[J]. 东北大学学报(自然科学版), 2024, 45(7): 1002-1010. |
| [3] | 田岸霖, 雷为民, 张鹏, 张伟. 一种基于编解码结构的多尺度边缘检测方法[J]. 东北大学学报(自然科学版), 2024, 45(7): 936-943. |
| [4] | 郭立新, 毕素涛, 赵明扬. 基于改进YOLOv4轻量化网络的机械手状态检测算法[J]. 东北大学学报(自然科学版), 2024, 45(6): 769-775. |
| [5] | 马原, 佘黎煌, 李佳蔚, 鲍喜荣. 基于注意力机制的自适应图卷积三维点云识别算法[J]. 东北大学学报(自然科学版), 2024, 45(6): 786-792. |
| [6] | 冯虎, 宋克臣, 崔文琦, 颜云辉. 基于元学习的带钢表面缺陷小样本语义分割[J]. 东北大学学报(自然科学版), 2024, 45(3): 354-360. |
| [7] | 单鹏, 张林, 肖洪明, 赵玉良. 融合多尺度注意力机制的冠状病毒肺炎CT诊断方法[J]. 东北大学学报(自然科学版), 2024, 45(12): 1673-1679. |
| [8] | 张执锦, 李鹤, 黄宇实, 王文学. 深度残差收缩网络在滚动轴承故障诊断中的应用[J]. 东北大学学报(自然科学版), 2024, 45(11): 1587-1594. |
| [9] | 郝博, 徐新岩, 赵玉欣, 闫俊伟. 基于改进YOLOv8的铆接孔表面缺陷检测[J]. 东北大学学报(自然科学版), 2024, 45(11): 1595-1603. |
| [10] | 刘梦园, 吴朝霞, 王金杨, 閤光磊. 基于TST-LSTM模型的烧结料层透气性预测[J]. 东北大学学报(自然科学版), 2024, 45(10): 1379-1385. |
| [11] | 赵越, 郝琨, 赵敬, 信俊昌. MMCSC:一种跨模态的假新闻检测方法[J]. 东北大学学报(自然科学版), 2024, 45(1): 18-25. |
| [12] | 孙颖, 周雅茹, 张雪英. 融合功能性副语言比例系数的语音情感识别[J]. 东北大学学报(自然科学版), 2024, 45(1): 40-48. |
| [13] | 姜杨, 刘成, 丁其川, 王力. 基于双注意力机制的COVID-19病灶CT图像分割方法[J]. 东北大学学报(自然科学版), 2023, 44(9): 1259-1268. |
| [14] | 周嵩, 高天寒. 基于注意力机制RNN模型的癫痫患者脑电信号识别方法[J]. 东北大学学报(自然科学版), 2023, 44(8): 1098-1103. |
| [15] | 丁其川, 王力, 刘成. 融合长距离信道注意力与病理特征的肺结节分类[J]. 东北大学学报(自然科学版), 2023, 44(4): 476-485. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||