东北大学学报(自然科学版) ›› 2024, Vol. 45 ›› Issue (6): 776-785.DOI: 10.12068/j.issn.1005-3026.2024.06.003
• 信息与控制 • 上一篇
韩东红1, 孔彦茹2( ), 展艺萌1, 刘源1
), 展艺萌1, 刘源1
收稿日期:2023-02-09
出版日期:2024-06-15
发布日期:2024-09-18
通讯作者:
孔彦茹
作者简介:韩东红(1968-),女,河北平山人,东北大学教授.
基金资助:
Dong-hong HAN1, Yan-ru KONG2(), Yi-meng ZHAN1, Yuan LIU1
Received:2023-02-09
Online:2024-06-15
Published:2024-09-18
Contact:
Yan-ru KONG
About author:KONG Yan-ru, Email: kong19960103@163.com摘要:
音乐情感识别研究在音乐智能推荐和音乐可视化等领域有着广阔的应用前景.针对该研究中存在的仅利用低层音频特征进行情感识别时效果有限且可解释性差的问题,首先,构建能够学习音符语义信息的基于乐器数字接口(MIDI)数据的情感识别模型ERMSLM(emotion recognition model based on skip?gram and LSTM using MIDI data),该模型的特征是由基于跳字模型(skip?gram)和长短期记忆(LSTM)网络提取的旋律特征,利用预训练的多层感知机(MLP)提取的调性特征以及手动构建的特征3部分连接而成;其次,构建融合歌词和社交标签的基于文本数据的情感识别模型ERMBT(emotion recognition model based on BERT using text data),其中歌词特征是由基于BERT(bidirectional encoder representations from trans formers)提取的情感特征、利用英文单词情感标准(ANEW)列表所构建的情感词典特征以及歌词的词频—逆文本频率(TF-IDF)特征所组成;最后,围绕MIDI和文本两种数据构建特征级融合和决策级融合两种多模态融合模型.实验结果表明,ERMSLM和ERMBT模型分别可达到56.93%,72.62%的准确率,决策级多模态融合模型效果更优.
中图分类号:
韩东红, 孔彦茹, 展艺萌, 刘源. 音乐多模态数据情感识别方法的研究[J]. 东北大学学报(自然科学版), 2024, 45(6): 776-785.
Dong-hong HAN, Yan-ru KONG, Yi-meng ZHAN, Yuan LIU. Research on Emotion Recognition Method of Music Multimodal Data[J]. Journal of Northeastern University(Natural Science), 2024, 45(6): 776-785.
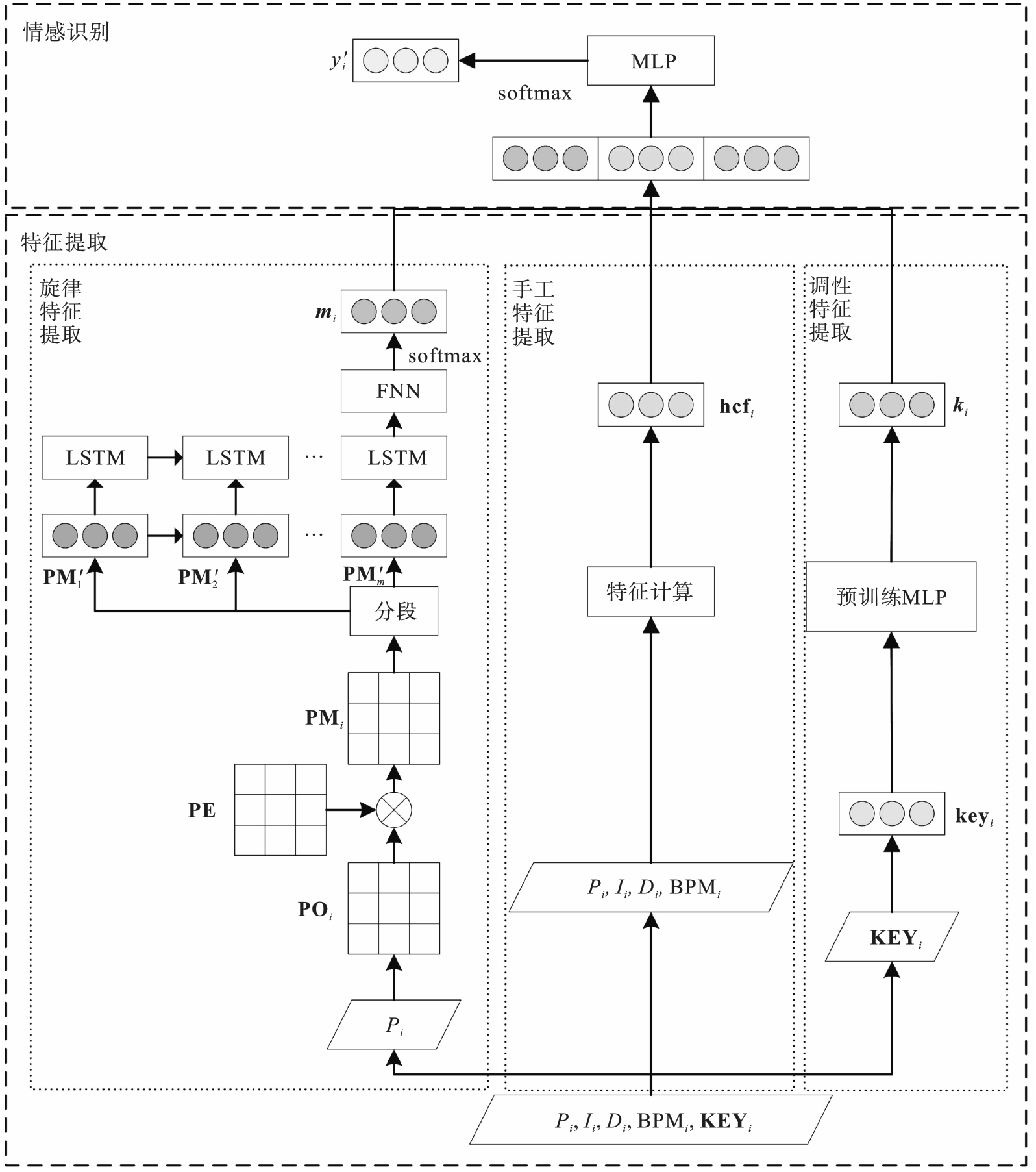
图1 ERMSLM框架图
Fig.1 Diagram of ERMSLM frame
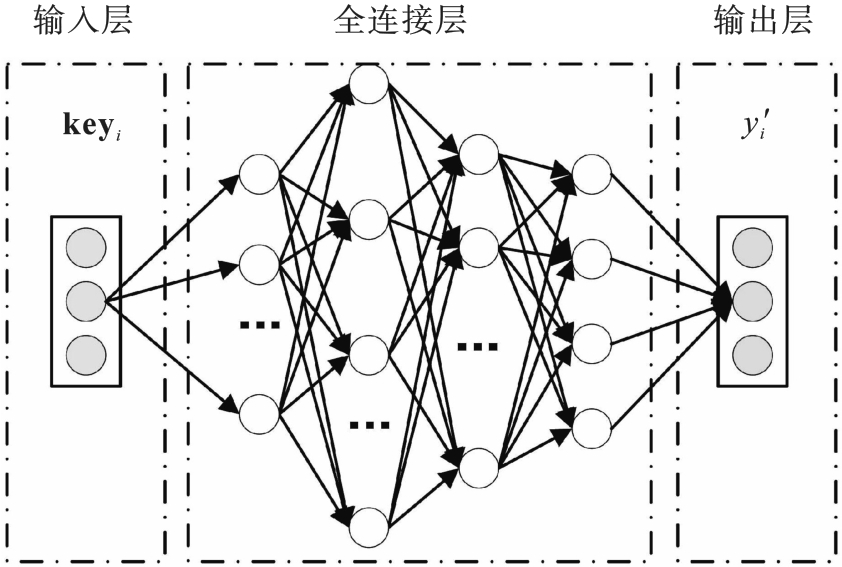
图2 预训练MLP
Fig.2 Pretrained MLP
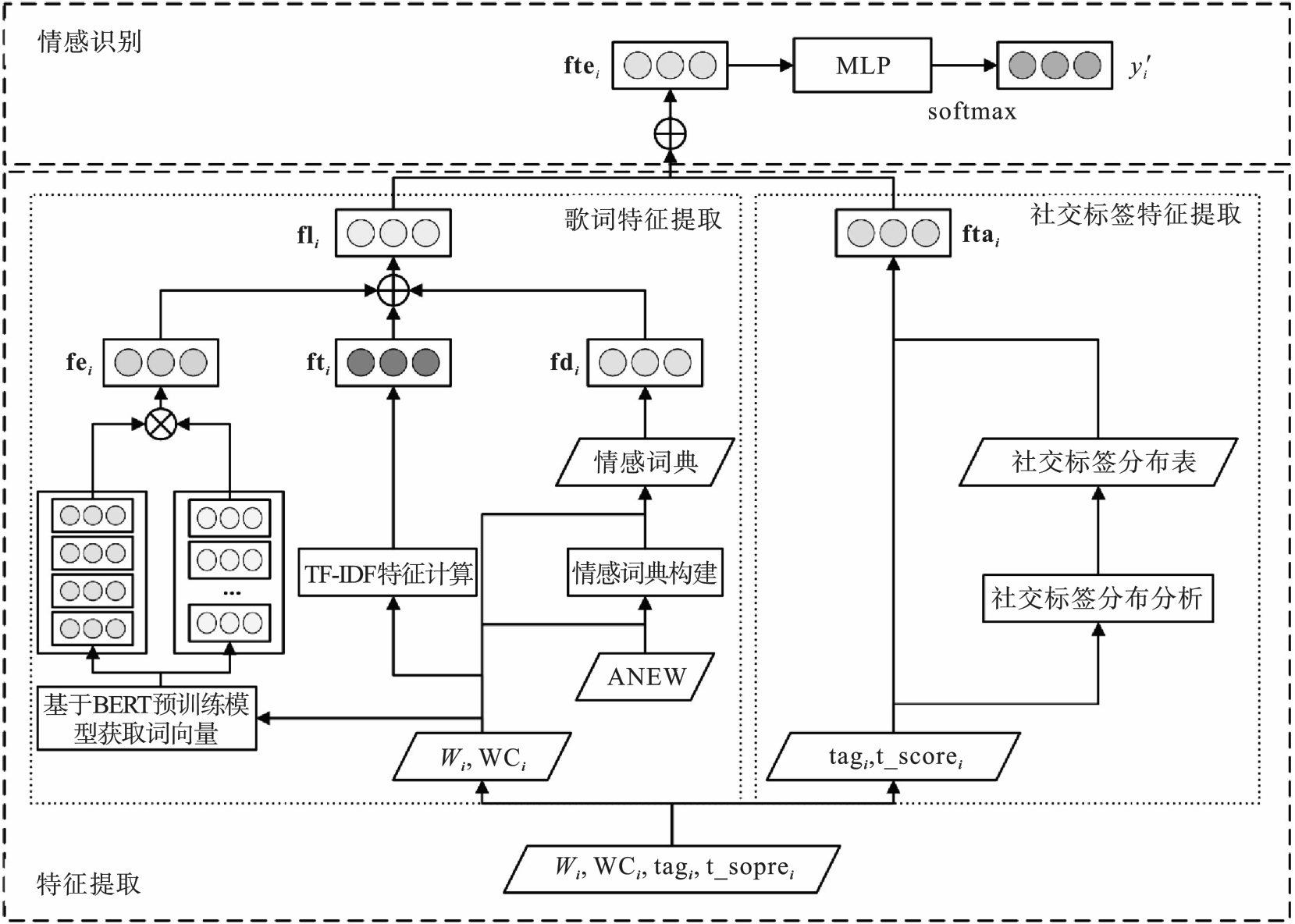
图3 ERMBT框架图
Fig.3 Diagram of ERMBT frame
| 词汇 | Happy | Anxious | Sad | Relaxed |
|---|---|---|---|---|
| Happy | — | 0.368 | 0.326 | 0.329 |
| Anxious | 0.368 | — | 0.416 | 0.276 |
| Sad | 0.326 | 0.416 | — | 0.341 |
| Relaxed | 0.329 | 0.276 | 0.341 | — |
表1 词汇相似度
Table 1 Lexical similarity
| 词汇 | Happy | Anxious | Sad | Relaxed |
|---|---|---|---|---|
| Happy | — | 0.368 | 0.326 | 0.329 |
| Anxious | 0.368 | — | 0.416 | 0.276 |
| Sad | 0.326 | 0.416 | — | 0.341 |
| Relaxed | 0.329 | 0.276 | 0.341 | — |
| 情感类别 | V +A+ | V -A+ | V -A- | V +A- |
|---|---|---|---|---|
| 单词数 | 199 | 133 | 48 | 119 |
表2 情感词典词汇分布
Table 2 Distribution of sentiment dictionary vocabulary
| 情感类别 | V +A+ | V -A+ | V -A- | V +A- |
|---|---|---|---|---|
| 单词数 | 199 | 133 | 48 | 119 |
输入:经过整理后的社交标签集Tag 输出:社交标签分布表 |
|---|
1) Begin 2) 由社交标签集Tag生成初始社交标签分布表 3) 读取标签汇总集T中的每个社交标签ti 4) For eachti inT 5) 若ti 在Tag的3个或4个子集中出现: 6) 从初始社交标签分布表中删除所有ti 7) 若ti 在社交标签集Tag的两个子集中出现: 8) 将ti 加入临时集合Temp 9) Endfor 10) 读取临时集合Temp中的每个社交标签ta i 11) For each ta i in Temp 12) 判断ta i 出现的位置,将其从靠后位置对应的 初始社交标签分布表中删除 13) Endfor 14) 获得社交标签分布表 15) End |
表3 社交标签分布分析算法
Table 3 Social tag distribution analysis algorithm
输入:经过整理后的社交标签集Tag 输出:社交标签分布表 |
|---|
1) Begin 2) 由社交标签集Tag生成初始社交标签分布表 3) 读取标签汇总集T中的每个社交标签ti 4) For eachti inT 5) 若ti 在Tag的3个或4个子集中出现: 6) 从初始社交标签分布表中删除所有ti 7) 若ti 在社交标签集Tag的两个子集中出现: 8) 将ti 加入临时集合Temp 9) Endfor 10) 读取临时集合Temp中的每个社交标签ta i 11) For each ta i in Temp 12) 判断ta i 出现的位置,将其从靠后位置对应的 初始社交标签分布表中删除 13) Endfor 14) 获得社交标签分布表 15) End |
| V +A+ | V -A+ | V -A- | V +A- |
|---|---|---|---|
| happy | heartbreak | sad | chillout |
| upbeat | angry | soft | soul |
| fun | epic | acoustic | smooth |
| party | heartache | emotional | relax |
| catchy | aggressive | dark | relaxing |
表4 社交标签分布
Table 4 Social tag distribution
| V +A+ | V -A+ | V -A- | V +A- |
|---|---|---|---|
| happy | heartbreak | sad | chillout |
| upbeat | angry | soft | soul |
| fun | epic | acoustic | smooth |
| party | heartache | emotional | relax |
| catchy | aggressive | dark | relaxing |
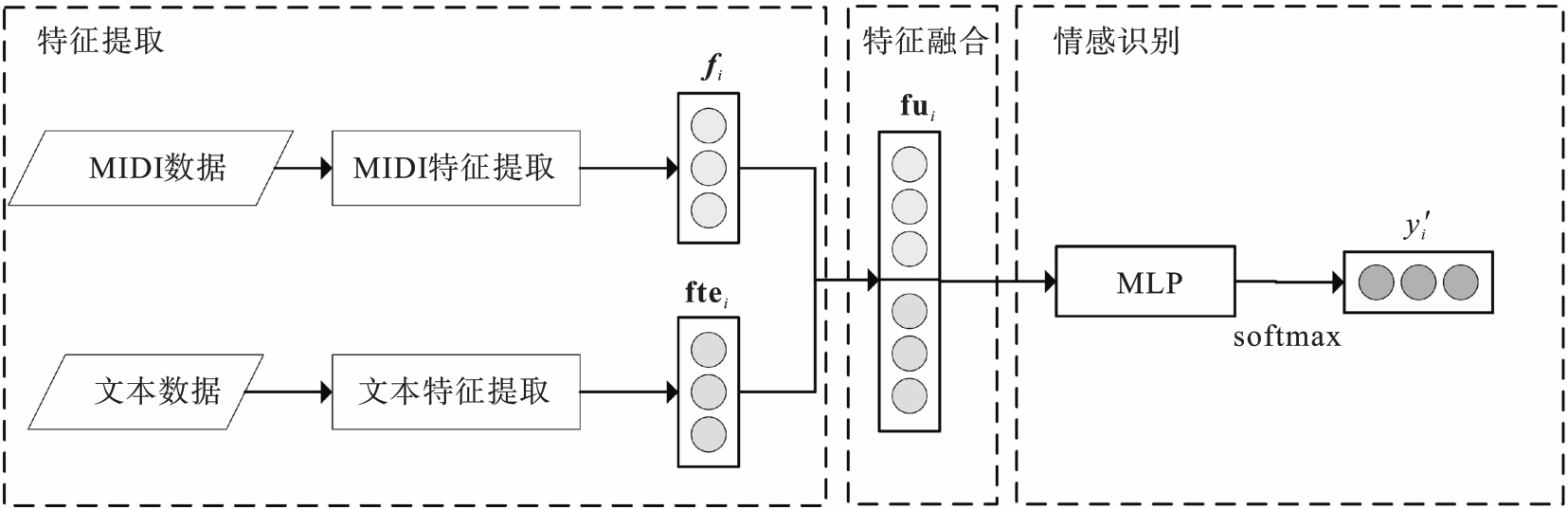
图4 FF-ERM框架图
Fig.4 Diagram of FF-ERM frame
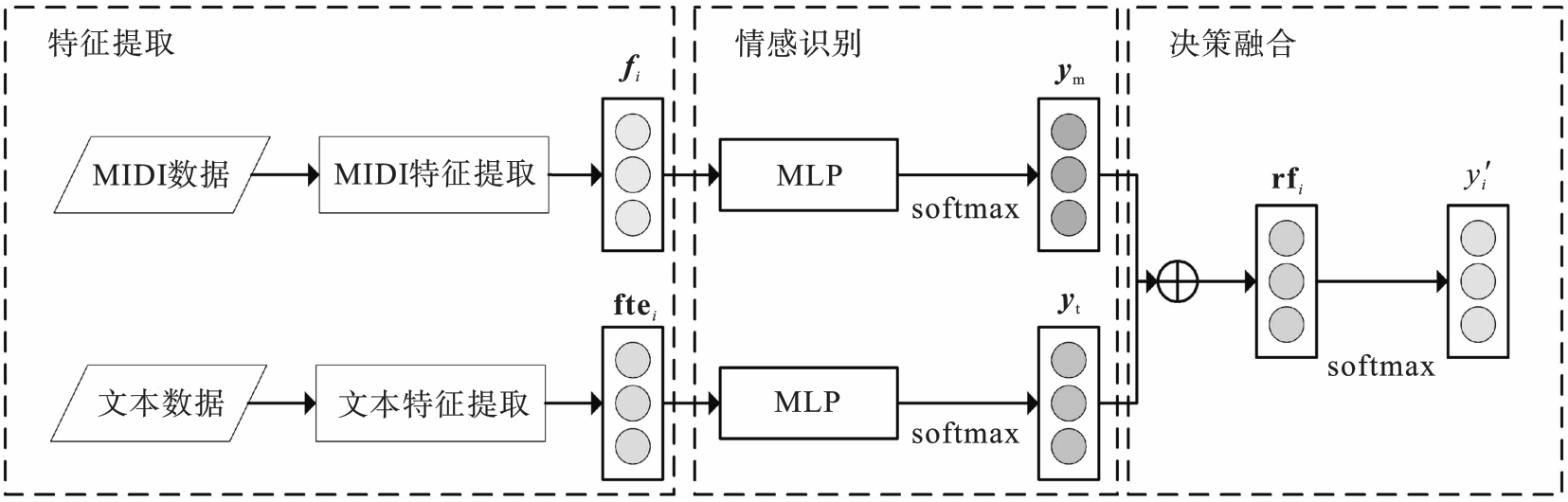
图5 DF-ERM框架图
Fig.5 Diagram of DF-ERM frame
| 类别 | 模型 | Accuracy | Marco-F1 |
|---|---|---|---|
| 对比实验 | 手工特征+神经网络 | 0.383 2 | 0.388 4 |
| MFCC+SVM | 0.551 1 | 0.538 6 | |
| MFCC+SVM | 0.554 7 | 0.519 4 | |
| MFCC+DBM | 0.551 1 | 0.594 4 | |
| 消融实验 | ERMSLM | 0.463 5 | 0.489 5 |
| ERMSLM | 0.547 4 | 0.597 2 | |
| ERMSLM | 0.569 3 | 0.599 9 |
表5 对比和消融实验结果
Table 5 Contrast and ablation experiment results
| 类别 | 模型 | Accuracy | Marco-F1 |
|---|---|---|---|
| 对比实验 | 手工特征+神经网络 | 0.383 2 | 0.388 4 |
| MFCC+SVM | 0.551 1 | 0.538 6 | |
| MFCC+SVM | 0.554 7 | 0.519 4 | |
| MFCC+DBM | 0.551 1 | 0.594 4 | |
| 消融实验 | ERMSLM | 0.463 5 | 0.489 5 |
| ERMSLM | 0.547 4 | 0.597 2 | |
| ERMSLM | 0.569 3 | 0.599 9 |
| 类别 | 模型 | Accuracy | Marco-F1 |
|---|---|---|---|
| 对比实验 | TFIDF+KNN | 0.534 2 | 0.462 6 |
| BOW+DBM | 0.551 1 | 0.594 4 | |
| 消融实验 | ERMBT | 0.551 1 | 0.594 4 |
| ERMBT | 0.715 3 | 0.743 4 | |
| ERMBT | 0.726 2 | 0.794 7 |
表6 对比和消融实验结果
Table 6 Contrast and ablation experiment results
| 类别 | 模型 | Accuracy | Marco-F1 |
|---|---|---|---|
| 对比实验 | TFIDF+KNN | 0.534 2 | 0.462 6 |
| BOW+DBM | 0.551 1 | 0.594 4 | |
| 消融实验 | ERMBT | 0.551 1 | 0.594 4 |
| ERMBT | 0.715 3 | 0.743 4 | |
| ERMBT | 0.726 2 | 0.794 7 |
| 模型名称 | V+A+ | V-A+ | V-A- | V+A- | 四类均值 |
|---|---|---|---|---|---|
| ERMSLM | 0.538 0 | 0.55 | 0.636 4 | 0.5 | 0.569 3 |
| ERMBT | 0.722 6 | 0.75 | 0.848 5 | 0.6 | 0.726 2 |
| FF-ERM | 0.711 5 | 0.70 | 0.787 9 | 0.6 | 0.708 0 |
| DF-ERM | 0.737 2 | 0.75 | 0.878 8 | 0.7 | 0.737 2 |
表7 每个情感类别上的准确率
Table 7 Accuracy on each sentiment category
| 模型名称 | V+A+ | V-A+ | V-A- | V+A- | 四类均值 |
|---|---|---|---|---|---|
| ERMSLM | 0.538 0 | 0.55 | 0.636 4 | 0.5 | 0.569 3 |
| ERMBT | 0.722 6 | 0.75 | 0.848 5 | 0.6 | 0.726 2 |
| FF-ERM | 0.711 5 | 0.70 | 0.787 9 | 0.6 | 0.708 0 |
| DF-ERM | 0.737 2 | 0.75 | 0.878 8 | 0.7 | 0.737 2 |
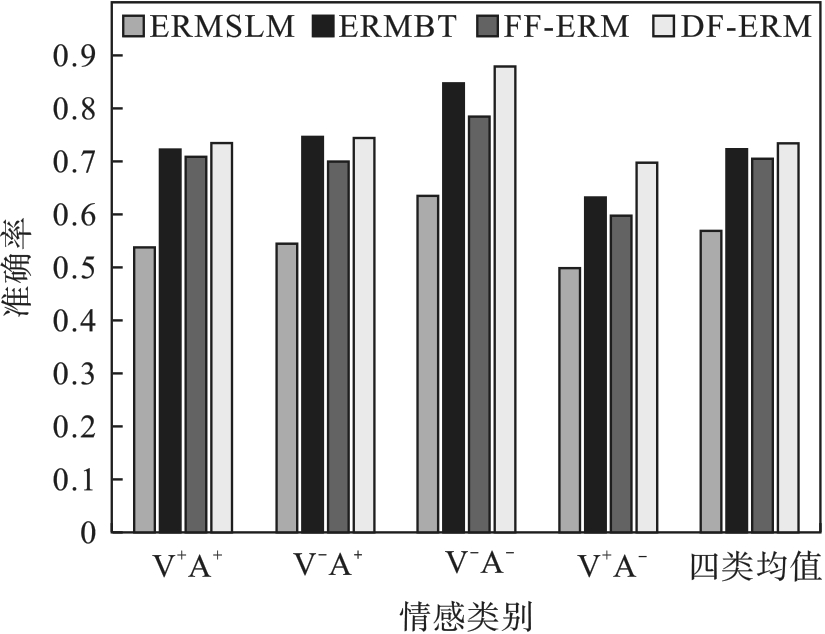
图6 实验结果图
Fig.6 Histogram of experiment results
| 1 | Han D H, Kong Y R, Han J Y,et al.A survey of music emotion recognition[J].Frontiers of Computer Science,2022,16(6):166335. |
| 2 | Jazi S Y, Kaedi M, Fatemi A.An emotion‑aware music recommender system:bridging the user’s interaction and music recommendation[J].Multimedia Tools and Application,2021,80(9):13559-13574. |
| 3 | Dharmapriya J, Dayarathne L, Diasena T,et al.Music emotion visualization through colour[C]//2021 International Conference on Electronics,Information,and Communication (ICEIC).Jeju,2021:1-6. |
| 4 | Novelli N, Proksch S.Am I (deep) blue?music‑making AI and emotional awareness[J].Frontiers in Neurorobotics,2022,16:897110. |
| 5 | Shukuroglou M, Roseman L, Wall M,et al.Changes in music‑evoked emotion and ventral striatal functional connectivity after psilocybin therapy for depression[J].Journal of Psychopharmacology,2023,37(1):70-79. |
| 6 | 陈晓鸥,杨德顺.音乐情感识别研究进展[J].复旦学报(自然科学版),2017,56(2):136-148. |
| Chen Xiao‑ou, Yang De‑shun.Research progresses in music emotion recognition[J].Journal of Fudan University (Natural Science),2017,56(2):136-148. | |
| 7 | Panda R, Malheiro R, Paiva R P.Novel audio features for music emotion recognition[J].IEEE Transactions on Affective Computing,2020,11(4):614-626. |
| 8 | Singh Y, Biswas A.Robustness of musical features on deep learning models for music genre classification[J].Expert Systems with Applications,2022,199:116879. |
| 9 | 邓永莉,吕愿愿,刘明亮,等.基于中高层特征的音乐情感识别模型[J].计算机工程与设计,2017,38(4):1029-1034. |
| Deng Yong‑li, Yuan‑yuan Lyu, Liu Ming‑liang,et al.Music emotion recognition based on middle and high level features[J].Computer Engineering and Design,2017,38(4):1029-1034. | |
| 10 | Qiu L, Zhong Y, Xie Q,et al.Multi‑modal integration of EEG-fNIRS for characterization of brain activity evoked by preferred music[J].Frontiers in Neurorobotics,2022,16:823435. |
| 11 | Delbouys R, Hennequin R, Piccoli F,et al.Music mood detection based on audio and lyrics with deep neural net[C]//Proceedings of the 19th International Society for Music Information Retrieval Conference(ISMIR).Paris,2018:370-375. |
| 12 | Jia X S.A music emotion classification model based on the improved convolutional neural network[J].Computational Intelligence and Neuroscience,2022,2022:6749622. |
| 13 | Liu X, Chen Q, Wu X,et al.CNN based music emotion classification[J].arXiv prePrint arXiv,2017:1704.05665. |
| 14 | Keelawat P, Thammasan N, Kijsirikul B,et al.Subject‐independent emotion recognition during music listening based on EEG using deep convolutional neural networks[C]//2019 IEEE 15th International Colloquium on Signal Processing & Its Applications (CSPA).Penang,2019:21-26. |
| 15 | Chowdhury S, Vall A, Haunscmid V,et al.Towards explainable music emotion recognition:the route via mid‑level features[C]//Proceedings of the 20th International Society for Music Information Retrieval Conference(ISMIR).Delft,2019:237-243. |
| 16 | Ma Y, Li X X, Xu M X,et al.Multi‑scale context based attention for dynamic music emotion prediction[C]//Proceedings of the 25th ACM international conference on Multimedia.Mountain View,2017:1443-1450. |
| 17 | Liu H, Fang Y, Huang Q.Music emotion recognition using a variant of recurrent neural network[C]//Proceedings of the International Conference on Mathematics,Modeling,Simulation and Statistics Application(MMSSA).Chengdu,2018:15-18. |
| 18 | Chang W H, Li J L, Lin Y S,et al.A genre‑affect relationship network with task‑specific uncertainty weighting for recognizing induced emotion in music[C]//2018 IEEE International Conference on Multimedia and Expo (ICME).San Diego,2018:1-6. |
| 19 | Soleymani M, Aljanaki A, Yang Y,et al.Emotional analysis of music:a comparison of methods[C]//Proceedings of the ACM Conference on Multimedia(MM).Orlando:ACM,2014:1161-1164. |
| 20 | Li X X, Tian J S, Xu M X,et al.DBLSTM‑based multi‐scale fusion for dynamic emotion prediction in music[C]//2016 IEEE International Conference on Multimedia and Expo (ICME).Seattle,2016:1-6. |
| 21 | Chaki S, Doshi P, Patnaik P,et al.Attentive RNNs for continuous‑time emotion prediction in music clips[C]//Proceedings of the 3rd Workshop in Affective Content Analysis co‑located with Thirty‑Fourth AAAI Conference on Artificial Intelligence.New York:AAAI,2020:36-46. |
| 22 | 韩文静,李海峰,阮华斌,等.语音情感识别研究进展综述[J].软件学报,2014,25(1):37-50. |
| Han Wen‑jing, Li Hai‑feng, Ruan Hua‑bin,et al.Review on speech emotion recognition[J].Journal of Software,2014,25(1):37-50. | |
| 23 | Zaanen M V, Kanters P.Automatic mood classification using TF*IDF based on lyrics[C]//Proceedings of the 11th International Society for Music Information Retrieval Conference(ISMIR).Utrecht,2010:75-80. |
| 24 | Wang X, Chen X, Yang D,et al.Music emotion classification of Chinese songs based on lyrics using TF*IDF and rhyme[C]//Proceedings of the 12th International Society for Music Information Retrieval Conference(ISMIR).Miami,2011:765-770. |
| 25 | Xie Z W, Liu L, Wu Y Z,et al.Learning TFIDF enhanced joint embedding for recipe‑image cross‑modal retrieval service[J].IEEE Transactions on Services Computing,2022,15(6):3304-3316. |
| 26 | Chen P L, Zhao L, Xin Z Y,et al.A scheme of MIDI music emotion classification based on fuzzy theme extraction and neural network[C]//2016 12th International Conference on Computational Intelligence and Security (CIS).Wuxi,2016:323-326. |
| 27 | Huang M Y, Rong W G, Arjannikov T,et al.Bi‑modal deep boltzmann machine based musical emotion classification[C]//International Conference on Artificial Neural Networks.Cham:Springer,2016:199-207. |
| [1] | 章伟琪, 王辉明. 混凝土抗压强度的可解释深度学习预测模型[J]. 东北大学学报(自然科学版), 2024, 45(5): 738-744. |
| [2] | 尉健一, 吴菁晶. 基于边缘计算的工业物联网中资源分配算法[J]. 东北大学学报(自然科学版), 2023, 44(8): 1072-1078. |
| [3] | 杨譞, 何占奇. 改进的两层BiLSTM的心电信号分割方法[J]. 东北大学学报(自然科学版), 2023, 44(12): 1705-1711. |
| [4] | 季策 , 王鑫, 耿蓉, 梁敏骏. 时变信道下基于LSTM的信道估计方法[J]. 东北大学学报(自然科学版), 2023, 44(11): 1521-1528. |
| [5] | 陈城, 史培新, 王占生, 贾鹏蛟. 基于融合多注意力机制的深度学习的盾构荷载预测方法[J]. 东北大学学报(自然科学版), 2023, 44(11): 1631-1638. |
| [6] | 刘伟嵬, 邓剑洋, 张靖文, 牛东东. 基于深度学习的挖掘机工作阶段的分类与识别[J]. 东北大学学报(自然科学版), 2023, 44(10): 1464-1474. |
| [7] | 李娟莉, 魏代良, 李博, 文小. 基于深度学习轻量化的改进SSD煤矸快速分选模型[J]. 东北大学学报(自然科学版), 2023, 44(10): 1474-1480. |
| [8] | 赵永, 焦诗卉, 赵乾百. 基于Mel频谱和LSTM-DCNN的矿山微震信号混合识别模型[J]. 东北大学学报(自然科学版), 2023, 44(10): 1481-1489. |
| [9] | 张雪峰, 王照乙. 基于双决斗深度Q网络的自动换道决策模型[J]. 东北大学学报(自然科学版), 2023, 44(10): 1369-1376. |
| [10] | 李占山, 宋志扬, 花昀峤. 一种基于自适应搜索的多模态多目标优化算法[J]. 东北大学学报(自然科学版), 2023, 44(10): 1408-1415. |
| [11] | 王瀛, 王泽浩, 李红, 黄文军. 基于深度学习的威胁情报领域命名实体识别[J]. 东北大学学报(自然科学版), 2023, 44(1): 33-39. |
| [12] | 顾德英, 罗聿伦, 李文超. 基于改进YOLOv5算法的复杂场景交通目标检测[J]. 东北大学学报(自然科学版), 2022, 43(8): 1073-1079. |
| [13] | 代茵, 刘维宾, 董昕阳, 宋雨朦. 基于注意力机制的U-Net脑脊液细胞分割[J]. 东北大学学报(自然科学版), 2022, 43(7): 944-950. |
| [14] | 李鸿儒, 任子洋, 黄友鹤, 于霞. 基于变权重奇异谱分析的心律不齐识别方法[J]. 东北大学学报(自然科学版), 2022, 43(3): 305-312. |
| [15] | 顾德英, 张松, 孟范伟. 基于单目视觉的车辆3D空间检测方法[J]. 东北大学学报(自然科学版), 2022, 43(3): 328-334. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||