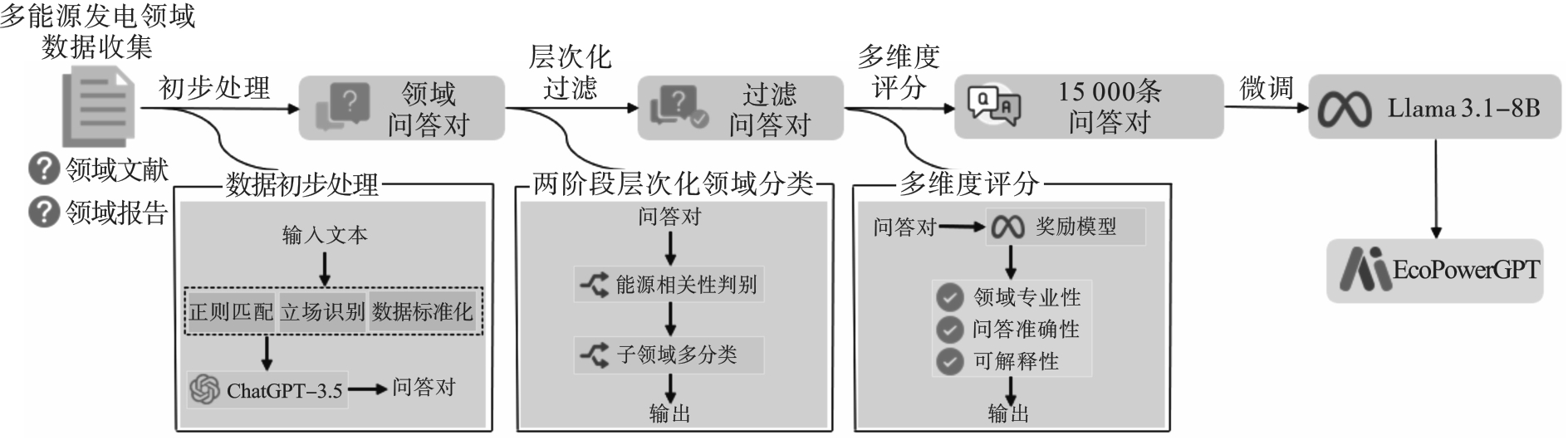
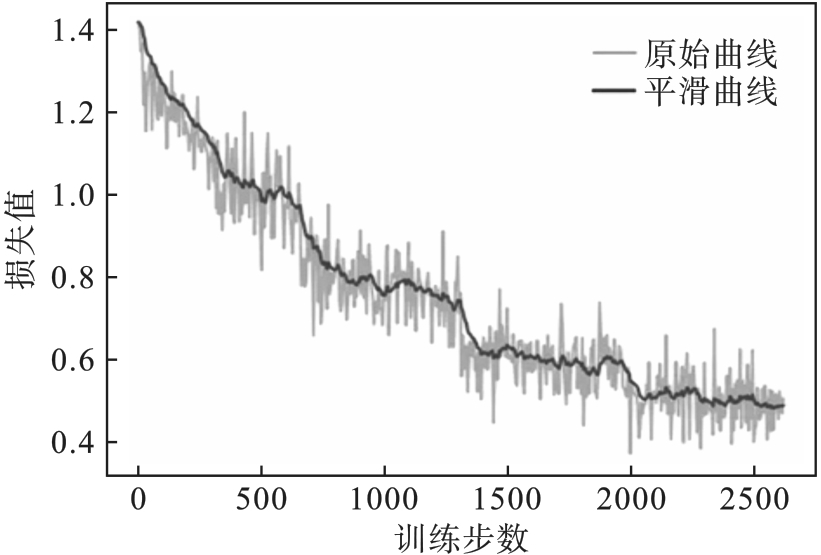
| [1] |
Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of Machine Learning Research, 2020, 21(1): 5485-5551.
|
| [2] |
周昆, 朱余韬, 陈志朋, 等. YuLan-Chat: 基于多阶段课程学习的大语言模型[J]. 计算机学报, 2025, 48(1): 1-18.
|
|
Zhou Kun, Zhu Yu-tao, Chen Zhi-peng, et al. YuLan-chat: a large language model based on multi-stage curriculum learning[J]. Chinese Journal of Computers, 2025, 48(1): 1-18.
|
| [3] |
OpenAI, Achiam J, Adler S, et al. GPT-4 technical report[EB/OL]. (2023-03-15) [2024-10-19]. .
|
| [4] |
田萱, 吴志超. 基于信息检索的知识库问答综述[J]. 计算机研究与发展, 2025, 62(2): 314-335.
|
|
Tian Xuan, Wu Zhi-chao. Review of knowledge base question answering based on information retrieval[J]. Journal of Computer Research and Development, 2025, 62(2): 314-335.
|
| [5] |
李诗晨, 王中卿, 周国栋. 大语言模型驱动的跨领域属性级情感分析[J]. 软件学报, 2025, 36(2): 644-659.
|
|
Li Shi-chen, Wang Zhong-qing, Zhou Guo-dong. LLM enhanced cross domain aspect-based sentiment analysis[J]. Journal of Software, 2025, 36(2): 644-659.
|
| [6] |
宫丽娜, 周易人, 乔羽, 等. 预训练模型在软件工程领域应用研究进展[J]. 软件学报, 2025, 36(1): 1-26.
|
|
Gong Li-na, Zhou Yi-ren, Qiao Yu, et al. Research progress of pre-trained model in software engineering[J]. Journal of Software, 2025, 36(1): 1-26.
|
| [7] |
Vakili T, Lamproudis A, Henriksson A, et al. Downstream task performance of BERT models pre-trained using automatically de-identified clinical data[C]//Proceedings of the Thirteenth Language Resources and Evaluation Conference. Marseille, 2022: 4245-4252.
|
| [8] |
Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C] // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, 2019: 4171-4186.
|
| [9] |
Song X Y, Salcianu A, Song Y, et al. Fast WordPiece tokenization[EB/OL]. (2020-12-31) [2024-10-19]. .
|
| [10] |
Grattafiori A, Dubey A, Jauhri A, et al. The Llama 3 herd of models[EB/OL]. (2024-07-31) [2024-10-19]. .
|
| [11] |
Basile P, Musacchio E, Polignano M, et al. LLaMAntino: LLaMA 2 models for effective text generation in Italian language[EB/OL]. (2023-12-15) [2024-10-19]. .
|
| [12] |
Fu Z H, Yang H R, So A M, et al. On the effectiveness of parameter-efficient fine-tuning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2023, 37(11): 12799-12807.
|
| [13] |
Hu E J, Shen Y L, Wallis P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. (2021-06-17) [2024-10-19]. .
|
| [14] |
Li X L, Liang P. Prefix-tuning: optimizing continuous prompts for generation[EB/OL]. (2021-01-01) [2024-10-19]. .
|
| [15] |
Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning[EB/OL]. (2021-04-17) [2024-10-19]. .
|
| [16] |
Dettmers T, Pagnoni A, Holtzman A, et al. QLoRA: efficient finetuning of quantized LLMs[EB/OL]. (2023-05-23) [2024-10-19]. .
|
| [17] |
Gao C, Zhang S Q. DLoRA: distributed parameter-efficient fine-tuning solution for large language model[EB/OL]. (2024-04-08) [2024-10-19]. .
|
| [18] |
Touvron H, Martin L, Stone K, et al. Llama 2: open foundation and fine-tuned chat models [EB/OL]. (2023-07-19) [2024-10-19]. .
|
| [19] |
Nguyen T T, Wilson C, Dalins J. Fine-tuning llama 2 large language models for detecting online sexual predatory chats and abusive texts [EB/OL]. (2023-08-28) [2024-10-19]. .
|
| [20] |
Yang A, Yang B S, Hui B Y, et al. Qwen2 technical report [EB/OL]. (2024-07-15) [2024-10-19]. .
|
| [21] |
Zhang S, Peng B C, Zhao X P, et al. LLaSA: large language and E-commerce shopping assistant[EB/OL]. (2024-08-02) [2024-10-19]. .
|
| [22] |
Yang A Y, Xiao B, Wang B N, et al. Baichuan 2: open large-scale language models[EB/OL]. (2023-09-19) [2024-10-19]. .
|
| [23] |
Cao Y Q, Yang L, Wei C, et al. Financial text sentiment classification based on Baichuan2 instruction finetuning model[C]//2023 5th International Conference on Frontiers Technology of Information and Computer (ICFTIC). Qiangdao, 2024: 403-406.
|
| [24] |
Jiang A Q, Sablayrolles A, Mensch A, et al. Mistral 7B [EB/OL]. (2023-10-10) [2024-10-19]. .
|
| [25] |
B T B, Chen J M. Performance assessment of ChatGPT versus bard in detecting Alzheimer’s dementia[J]. Diagnostics, 2024, 14(8): 817.
|
| [26] |
Lin C Y. ROUGE: a package for automatic evaluation of summaries[C]//Annual Meeting of the Association for Computational Linguistics.Stroudsburg, 2004: 74-81.
|
| [27] |
Papineni K, Roukos S, Ward T, et al. Bleu: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics-ACL ’02. Philadelphia. 2001: 311-318.
|
 ), Yan-liang GUO1,2, Rui-ting QU3, Qing SONG3
), Yan-liang GUO1,2, Rui-ting QU3, Qing SONG3