东北大学学报(自然科学版) ›› 2026, Vol. 47 ›› Issue (1): 75-81.DOI: 10.12068/j.issn.1005-3026.2026.20250040
董闯1, 栗伟1,2( ), 巴聪1, 覃文军1,2
), 巴聪1, 覃文军1,2
收稿日期:2025-04-22
出版日期:2026-01-15
发布日期:2026-03-17
通讯作者:
栗伟
作者简介:董 闯(1994—),男,辽宁本溪人,东北大学博士研究生.
基金资助:
Chuang DONG1, Wei LI1,2(), Cong BA1, Wen-jun TAN1,2
Received:2025-04-22
Online:2026-01-15
Published:2026-03-17
Contact:
Wei LI
摘要:
针对当前视频-文本检索方法未能有效结合时间信息与相关性信息进行联合建模的问题,提出一种基于跨模态注意力机制的视频-文本检索方法.首先,利用预训练的大规模图像-文本模型提取文本和视频帧的嵌入表示,通过知识迁移缓解不同模态数据之间的异质性问题.然后,使用联合文本-帧跨模态注意力机制模块,同时编码视频帧之间的时间信息以及视频帧与文本之间的相关性信息,捕获更具竞争力的视频特征表示.最后,利用交叉熵损失函数约束模型训练.通过对比实验验证,该方法能够有效捕获视频帧的时间信息和相关性信息,在MSR-VTT(microsoft research video to text)和LSMDC(large-scale movie description challenge)数据集上取得具有竞争力的效果.
中图分类号:
董闯, 栗伟, 巴聪, 覃文军. 基于跨模态注意力机制的视频-文本检索方法[J]. 东北大学学报(自然科学版), 2026, 47(1): 75-81.
Chuang DONG, Wei LI, Cong BA, Wen-jun TAN. Video-Text Retrieval Method Based on Cross-Modal Attention Mechanism[J]. Journal of Northeastern University(Natural Science), 2026, 47(1): 75-81.
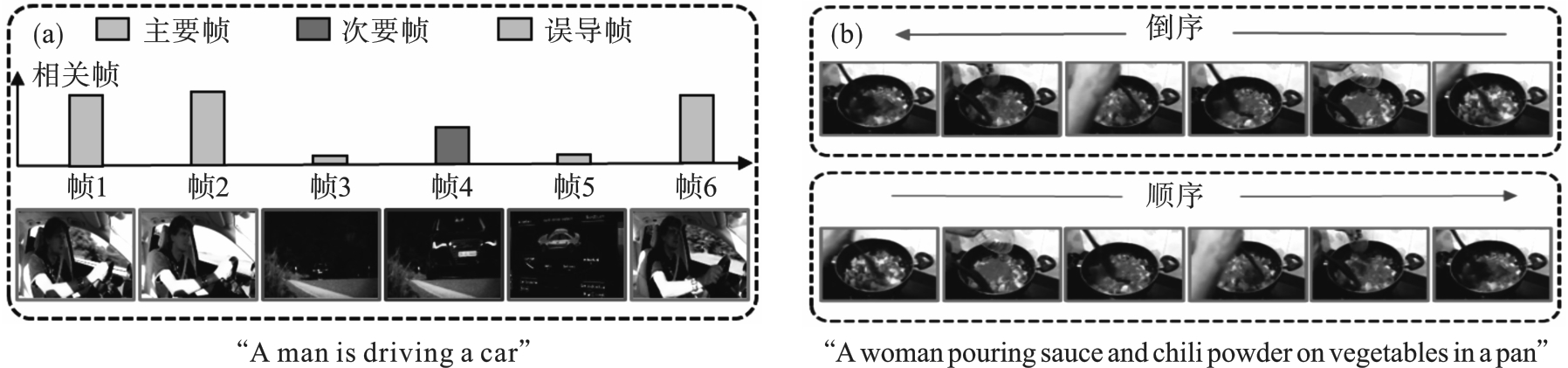
图1 图像知识迁移到视频过程中相关性信息和时间信息的影响
Fig.1 Impact of relevance information and temporal information during process of transferring image knowledge
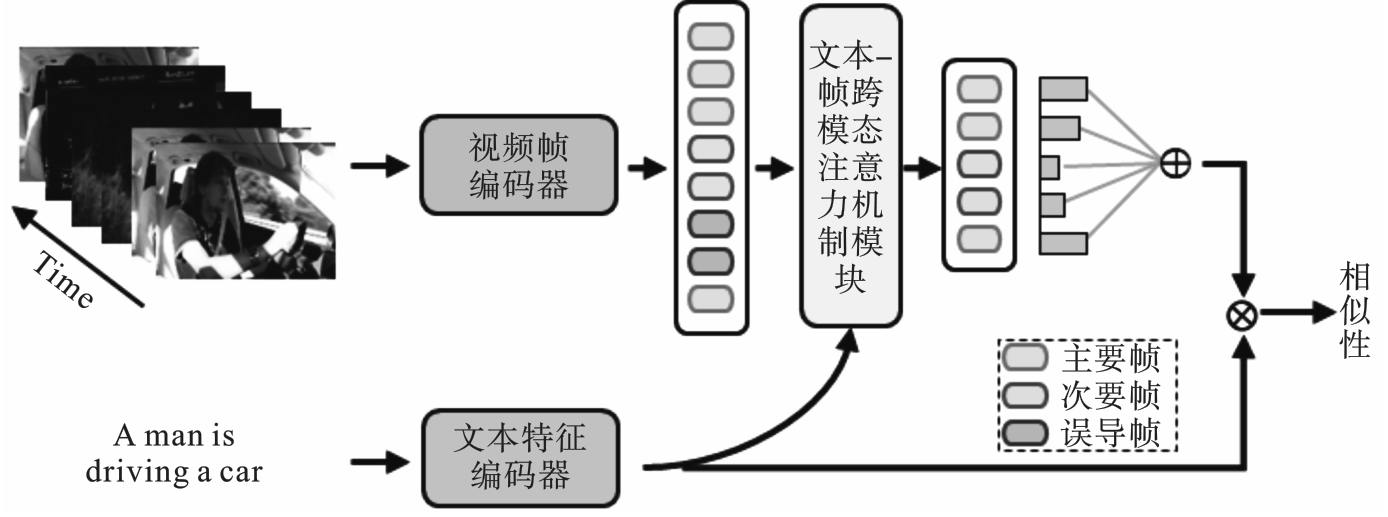
图2 基于跨模态注意力机制的视频-文本检索模型架构
Fig.2 Architecture of video-text retrieval model based on cross-modal attention mechanism
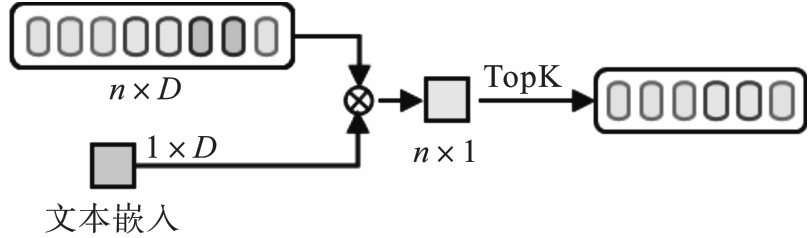
图3 TopK文本-帧跨模态注意力机制
Fig.3 TopK text-frame cross-modal attention mechanism
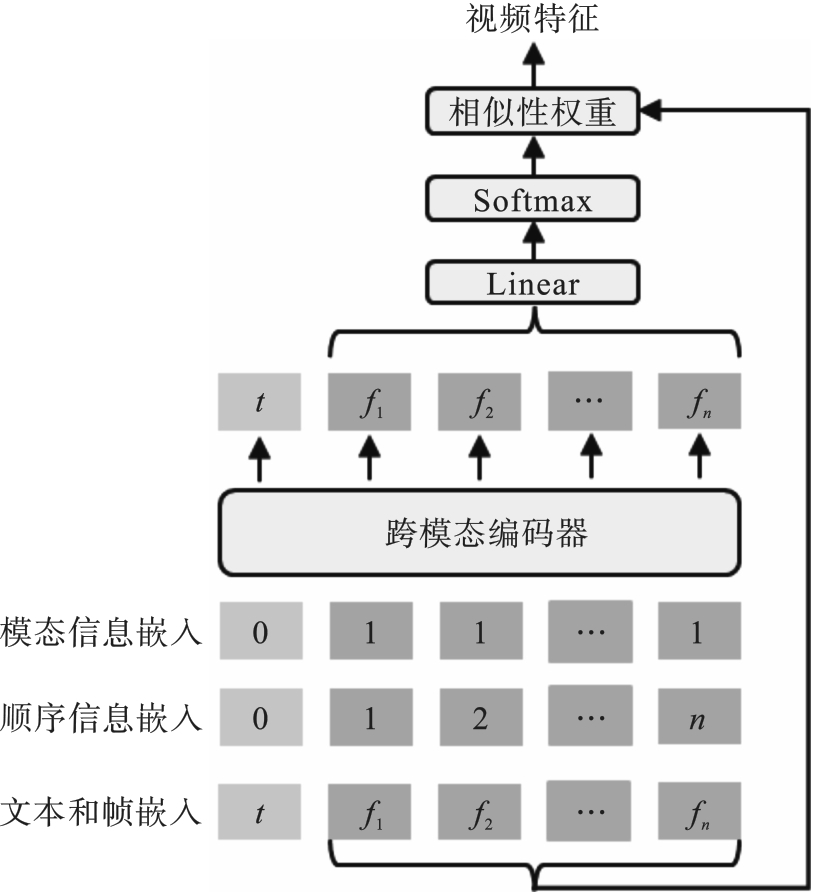
图4 联合文本-帧跨模态注意力机制
Fig.4 Joint text-frame cross-modal attention mechanism
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| ActBERT[ | 8.6 | 23.4 | 33.1 | 36.0 | — |
| Howto100M[ | 14.9 | 40.2 | 52.8 | 9.0 | — |
| ClipBERT[ | 22.0 | 46.8 | 59.9 | 6.0 | — |
| All-in-one[ | 34.4 | 65.4 | 75.8 | — | — |
| CLIP4Clip[ | 42.0 | 68.6 | 78.7 | 2.0 | 16.2 |
| X-Pool[ | 43.9 | 72.5 | 82.3 | 2.0 | 14.6 |
| Ours | 44.6 | 73.1 | 84.0 | 2.0 | 12.4 |
表1 MSR-VTT-7K文本到视频检索结果 (MSR-VTT-7K)
Table 1 Text-to-video retrieval results on
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| ActBERT[ | 8.6 | 23.4 | 33.1 | 36.0 | — |
| Howto100M[ | 14.9 | 40.2 | 52.8 | 9.0 | — |
| ClipBERT[ | 22.0 | 46.8 | 59.9 | 6.0 | — |
| All-in-one[ | 34.4 | 65.4 | 75.8 | — | — |
| CLIP4Clip[ | 42.0 | 68.6 | 78.7 | 2.0 | 16.2 |
| X-Pool[ | 43.9 | 72.5 | 82.3 | 2.0 | 14.6 |
| Ours | 44.6 | 73.1 | 84.0 | 2.0 | 12.4 |
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 26.6 | 57.1 | 69.6 | 4.0 | 24.0 |
| FROZEN[ | 32.5 | 61.5 | 71.2 | 3.0 | — |
| All-in-one[ | 37.9 | 68.1 | 77.1 | — | — |
| MAC[ | 38.9 | 63.1 | 73.9 | 3.0 | — |
| Clover[ | 40.5 | 69.8 | 79.4 | 2.0 | — |
| CLIP4Clip[ | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| RVTR[ | 45.8 | 73.0 | 83.5 | — | — |
| X-CLIP[ | 46.1 | 73.0 | 83.1 | 2.0 | 13.2 |
| X-Pool[ | 46.9 | 72.8 | 82.2 | 2.0 | 14.3 |
| STAN[ | 46.9 | 72.8 | 82.8 | 2.0 | — |
| DGL[ | 47.0 | 70.4 | 81.0 | — | 16.4 |
| TS2-Net[ | 47.0 | 74.5 | 83.8 | 2.0 | 13.0 |
| TABLE[ | 47.1 | 74.3 | 82.9 | 2.0 | 13.4 |
| Ours | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
表2 MSR-VTT-9K文本到视频检索结果 (MSR-VTT-9K)
Table 2 Text-to-video retrieval results on
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 26.6 | 57.1 | 69.6 | 4.0 | 24.0 |
| FROZEN[ | 32.5 | 61.5 | 71.2 | 3.0 | — |
| All-in-one[ | 37.9 | 68.1 | 77.1 | — | — |
| MAC[ | 38.9 | 63.1 | 73.9 | 3.0 | — |
| Clover[ | 40.5 | 69.8 | 79.4 | 2.0 | — |
| CLIP4Clip[ | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| RVTR[ | 45.8 | 73.0 | 83.5 | — | — |
| X-CLIP[ | 46.1 | 73.0 | 83.1 | 2.0 | 13.2 |
| X-Pool[ | 46.9 | 72.8 | 82.2 | 2.0 | 14.3 |
| STAN[ | 46.9 | 72.8 | 82.8 | 2.0 | — |
| DGL[ | 47.0 | 70.4 | 81.0 | — | 16.4 |
| TS2-Net[ | 47.0 | 74.5 | 83.8 | 2.0 | 13.0 |
| TABLE[ | 47.1 | 74.3 | 82.9 | 2.0 | 13.4 |
| Ours | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 12.9 | 29.9 | 40.1 | 19.3 | 75.0 |
| FROZEN[ | 15.0 | 30.8 | 39.8 | 20.0 | — |
| RVTR[ | 19.2 | 38.0 | 47.0 | — | — |
| DGL[ | 21.6 | 39.3 | 49.0 | — | 64.4 |
| CLIP4Clip[ | 22.6 | 41.0 | 49.1 | 11.0 | 61.0 |
| X-CLIP[ | 23.3 | 43.0 | 56.0 | — | — |
| TS2-Net[ | 23.4 | 42.3 | 50.9 | 9.0 | 56.9 |
| STAN[ | 23.7 | 42.7 | 51.8 | 9.0 | — |
| TABLE[ | 24.3 | 44.9 | 53.7 | 8.0 | 52.7 |
| Clover[ | 24.8 | 44.0 | 54.5 | 8.0 | — |
| X-Pool[ | 25.2 | 43.7 | 53.5 | 8.0 | 53.2 |
| Ours | 25.4 | 43.8 | 54.2 | 8.0 | 52.8 |
表3 LSMDC文本到视频检索结果
Table 3 Text-to-video retrieval results on LSMDC
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 12.9 | 29.9 | 40.1 | 19.3 | 75.0 |
| FROZEN[ | 15.0 | 30.8 | 39.8 | 20.0 | — |
| RVTR[ | 19.2 | 38.0 | 47.0 | — | — |
| DGL[ | 21.6 | 39.3 | 49.0 | — | 64.4 |
| CLIP4Clip[ | 22.6 | 41.0 | 49.1 | 11.0 | 61.0 |
| X-CLIP[ | 23.3 | 43.0 | 56.0 | — | — |
| TS2-Net[ | 23.4 | 42.3 | 50.9 | 9.0 | 56.9 |
| STAN[ | 23.7 | 42.7 | 51.8 | 9.0 | — |
| TABLE[ | 24.3 | 44.9 | 53.7 | 8.0 | 52.7 |
| Clover[ | 24.8 | 44.0 | 54.5 | 8.0 | — |
| X-Pool[ | 25.2 | 43.7 | 53.5 | 8.0 | 53.2 |
| Ours | 25.4 | 43.8 | 54.2 | 8.0 | 52.8 |
| K | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 1 | 41.5 | 68.8 | 78.6 | 2.0 | 13.5 |
| 2 | 43.4 | 70.8 | 81.6 | 2.0 | 13.5 |
| 4 | 44.2 | 70.5 | 81.2 | 2.0 | 14.1 |
| 6 | 43.3 | 71.0 | 80.9 | 2.0 | 14.0 |
| 8 | 43.5 | 69.7 | 80.3 | 2.0 | 14.6 |
| 10 | 43.1 | 68.9 | 79.9 | 2.0 | 15.2 |
| 12 | 42.2 | 69.5 | 79.5 | 2.0 | 15.5 |
表4 不同K的消融实验结果
Table 4 Ablation experiment results of different K
| K | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 1 | 41.5 | 68.8 | 78.6 | 2.0 | 13.5 |
| 2 | 43.4 | 70.8 | 81.6 | 2.0 | 13.5 |
| 4 | 44.2 | 70.5 | 81.2 | 2.0 | 14.1 |
| 6 | 43.3 | 71.0 | 80.9 | 2.0 | 14.0 |
| 8 | 43.5 | 69.7 | 80.3 | 2.0 | 14.6 |
| 10 | 43.1 | 68.9 | 79.9 | 2.0 | 15.2 |
| 12 | 42.2 | 69.5 | 79.5 | 2.0 | 15.5 |
| 类型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 基准 | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| 无时间编码 | 46.8 | 72.5 | 82.4 | 2.0 | 14.2 |
| 有时间编码 | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
表5 时间信息编码实验结果 (encoding)
Table 5 Experimental results of temporal information
| 类型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 基准 | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| 无时间编码 | 46.8 | 72.5 | 82.4 | 2.0 | 14.2 |
| 有时间编码 | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
| [1] | Radford A, Kim J W, Hallacy C, et al.Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning.Vienna: PMLR, 2021: 8748-8763. |
| [2] | Luo H S, Ji L, Zhong M, et al.CLIP4Clip: an empirical study of CLIP for end to end video clip retrieval and captioning[J].Neurocomputing, 2022, 508: 293-304. |
| [3] | Ma Y W, Xu G H, Sun X S, et al.X-CLIP: end-to-end multi-grained contrastive learning for video-text retrieval[C]// Proceedings of the 30th ACM International Conference on Multimedia.New York: Association for Computing Machinery, 2022: 638-647. |
| [4] | Wu W H, Luo H P, Fang B, et al.Cap4Video: what can auxiliary captions do for text-video retrieval?[C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver BC: IEEE, 2023: 10704-10713. |
| [5] | Fang H, Xiong P F, Xu L H, et al.Transferring image-CLIP to video-text retrieval via temporal relations[J].IEEE Transactions on Multimedia, 2023, 25: 7772-7785. |
| [6] | Bertasius G, Wang H, Torresani L.Is space-time attention all you need for video understanding? [C]//Proceedings of the 38th International Conference on Machine Learning.Vienna: PMLR, 2021: 813-824. |
| [7] | Liu R Y, Huang J J, Li G, et al.Revisiting temporal modeling for CLIP-based image-to-video knowledge transferring[C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver BC: IEEE, 2023: 6555-6564. |
| [8] | Xu J, Mei T, Yao T, et al.MSR-VTT: a large video description dataset for bridging video and language[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas: IEEE, 2016: 5288-5296. |
| [9] | Gorti S K, Vouitsis N, Ma J W, et al. X-Pool: cross-modal language-video attention for text-video retrieval[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans: IEEE, 2022: 5006-5015. |
| [10] | Miech A, Laptev I, Sivic J.Learning a text-video embedding from incomplete and heterogeneous data [EB/OL].(2018-04-07) [2024-10-24].. |
| [11] | Gabeur V, Sun C, Alahari K, et al. Multi-modal Transformer for video retrieval[C]// Computer Vision-ECCV 2020: 16th European Conference.Glasgow: Springer International Publishing, 2020: 214-229. |
| [12] | Liu Y, Albanie S, Nagrani A, et al.Use what you have: video retrieval using representations from collaborative experts [EB/OL].(2019-07-31) [2024-10-24].. |
| [13] | Jordan M I, Jacobs R A.Hierarchical mixtures of experts and the EM algorithm[J].Neural Computation, 1994, 6(2): 181-214. |
| [14] | Miech A, Zhukov D, Alayrac J B, et al.HowTo100M: learning a text-video embedding by watching hundred million narrated video clips[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Seoul: IEEE, 2019: 2630-2640. |
| [15] | Bain M, Nagrani A, Varol G, et al. Frozen in time: a joint video and image encoder for end-to-end retrieval[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Montreal: IEEE, 2021: 1728-1738. |
| [16] | Zhu L C, Yang Y.ActBERT: learning global-local video-text representations[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle: IEEE, 2020: 8743-8752. |
| [17] | Hochreiter S, Schmidhuber J. Long short-term memory[J].Neural Computation, 1997,9(8): 1735-1780. |
| [18] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach: Curran Associates Inc., 2017: 6000-6010. |
| [19] | Buch S, Eyzaguirre C, Gaidon A, et al.Revisiting the “Video” in video-language understanding[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 2907-2917. |
| [20] | Rohrbach A, Torabi A, Rohrbach M, et al.Movie description[J].International Journal of Computer Vision, 2017, 123(1): 94-120. |
| [21] | Kingma D P, Ba J.Adam: a method for stochastic optimization[EB/OL].(2017-01-30) [2024-10-24].. |
| [22] | Loshchilov I, Hutter F.SGDR: stochastic gradient descent with warm restarts[EB/OL].(2017-05-30) [2024-10-24].. |
| [23] | Zhao S, Zhu L C, Wang X H, et al.CenterCLIP: token clustering for efficient text-video retrieval[C]//Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval.Madrid: ACM, 2022: 970-981. |
| [24] | Wang J P, Ge Y X, Yan R, et al.All in one: exploring unified video-language pre-training[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Vancouver BC: IEEE, 2023: 6598-6608. |
| [25] | Shu F X, Chen B L, Liao Y, et al.MAC: masked contrastive pre-training for efficient video-text retrieval[J].IEEE Transactions on Multimedia, 2024, 26: 9962-9972. |
| [26] | Huang J J, Li Y N, Feng J S, et al.Clover: towards a unified video-language alignment and fusion model[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver BC: IEEE, 2023: 14856-14866. |
| [27] | Zhang H W, Yang Y, Qi F, et al.Robust video-text retrieval via noisy pair calibration[J]. IEEE Transactions on Multimedia, 2023, 25: 8632-8645. |
| [28] | Yang X, Zhu L, Wang X, et al. DGL: dynamic global-local prompt tuning for text-video retrieval[C]//Proceedings of the AAAI Conference on Artificial Intelligence.Vancouver: AAAI Press, 2024: 6540-6548. |
| [29] | Liu Y Q, Xiong P F, Xu L H, et al.TS2-net: token shift and selection transformer for text-video retrieval[C]// European Conference on Computer Vision.Cham: Springer, 2022: 319-335. |
| [30] | Chen Y Z, Wang J, Lin L J, et al.Tagging before alignment: integrating multi-modal tags for video-text retrieval[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Washington DC: AAAI Press, 2023: 396-404. |
| [1] | 栗潇通, 宋小龙, 范金鑫, 吴朝霞. 基于混合特征选择的BiGRU-Att烧结矿转鼓指数预测模型[J]. 东北大学学报(自然科学版), 2026, 47(1): 107-114. |
| [2] | 魏颖, 张家鹏, 崔佳琦, 黄通. 结合运动信息与双重注意力机制的两阶段SiamCAR跟踪算法[J]. 东北大学学报(自然科学版), 2025, 46(9): 9-16. |
| [3] | 李荟, 韩晓飞, 朱万成, 毛嘉石. 基于ICEEMDAN与Attention-LSTM的矿山边坡位移预测[J]. 东北大学学报(自然科学版), 2025, 46(7): 163-170. |
| [4] | 刘纪红, 时瑞瑞. 基于YOLOv8改进的无人机视觉小目标检测模型[J]. 东北大学学报(自然科学版), 2025, 46(12): 29-37. |
| [5] | 邹慧, 佘黎煌, 陈烨涵, 乐意. 基于几何注意力机制的三维手部姿势估计算法[J]. 东北大学学报(自然科学版), 2025, 46(10): 44-50. |
| [6] | 沙晓鹏, 谢德瀚, 郭周鹏, 孙凯. LIDD-Net:基于深度学习的轻量级工业产品缺陷检测方法[J]. 东北大学学报(自然科学版), 2025, 46(10): 18-26. |
| [7] | 吕真真, 房立金, 赵乾坤, 万应才. 基于改进的YOLOv8的PCB瑕疵检测[J]. 东北大学学报(自然科学版), 2025, 46(10): 1-9. |
| [8] | 李海燕, 乔仁超, 李海江, 陈泉. 基于全局残差注意力和门控特征融合的CNN-Transformer去雾算法[J]. 东北大学学报(自然科学版), 2025, 46(1): 26-34. |
| [9] | 万应才, 房立金, 赵乾坤. 基于跨模态融合的玻璃类似物分割方法[J]. 东北大学学报(自然科学版), 2025, 46(1): 1-8. |
| [10] | 刘炎, 卜齐杰, 赵红晨, 郭鑫. 基于多源异构信息的浮选过程运行状态评价[J]. 东北大学学报(自然科学版), 2024, 45(9): 1217-1226. |
| [11] | 田岸霖, 雷为民, 张鹏, 张伟. 一种基于编解码结构的多尺度边缘检测方法[J]. 东北大学学报(自然科学版), 2024, 45(7): 936-943. |
| [12] | 刘伟嵬, 邱佳鹤, 胡光大, 刘泽远. 基于改进YOLOv5的退役轴类零件表面损伤检测方法[J]. 东北大学学报(自然科学版), 2024, 45(7): 1002-1010. |
| [13] | 马原, 佘黎煌, 李佳蔚, 鲍喜荣. 基于注意力机制的自适应图卷积三维点云识别算法[J]. 东北大学学报(自然科学版), 2024, 45(6): 786-792. |
| [14] | 郭立新, 毕素涛, 赵明扬. 基于改进YOLOv4轻量化网络的机械手状态检测算法[J]. 东北大学学报(自然科学版), 2024, 45(6): 769-775. |
| [15] | 冯虎, 宋克臣, 崔文琦, 颜云辉. 基于元学习的带钢表面缺陷小样本语义分割[J]. 东北大学学报(自然科学版), 2024, 45(3): 354-360. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||