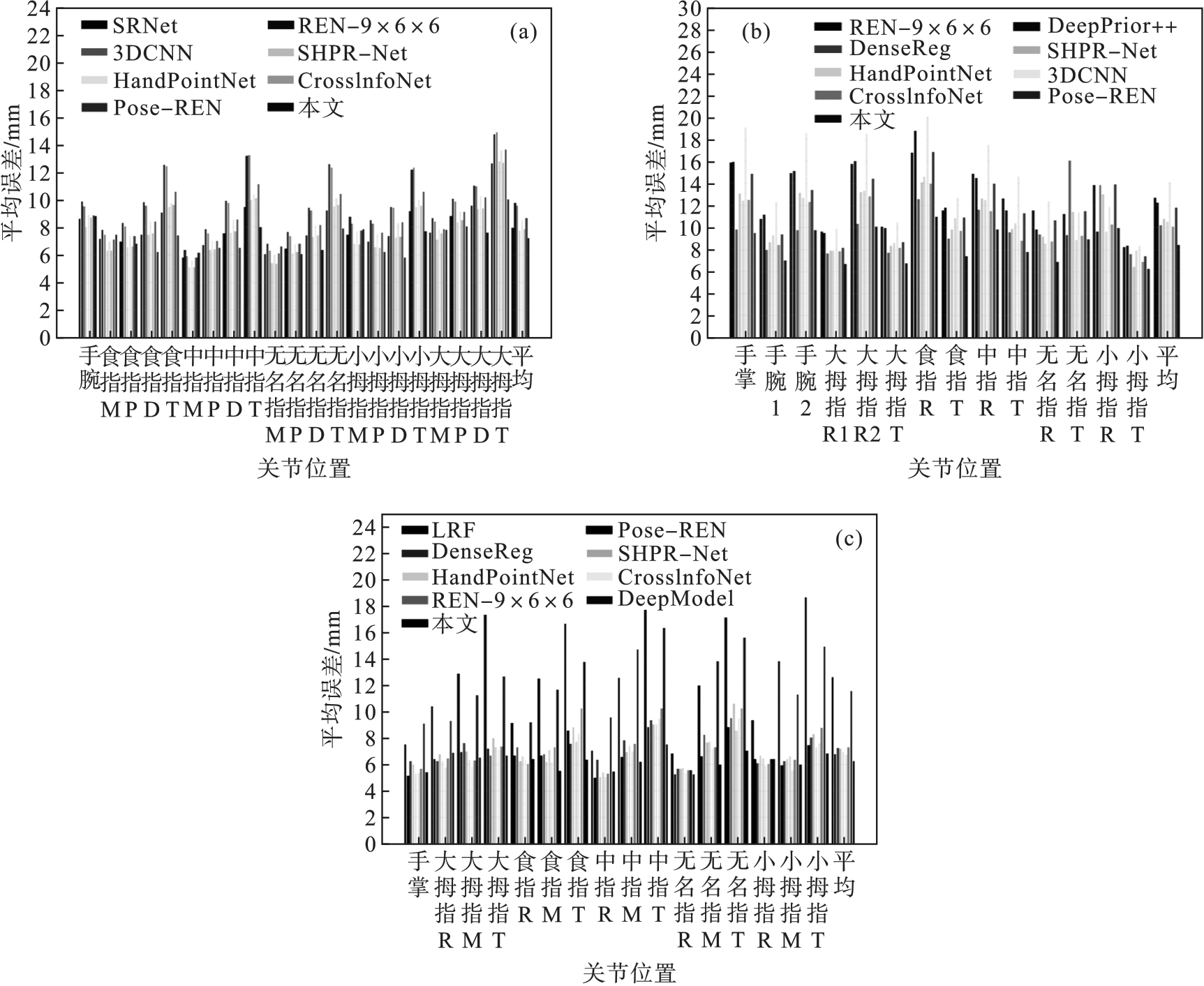
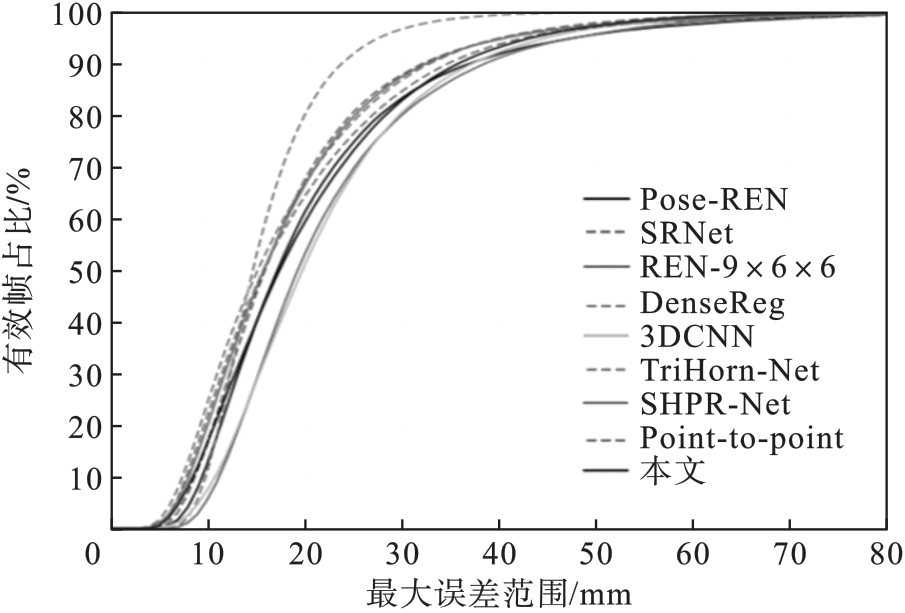
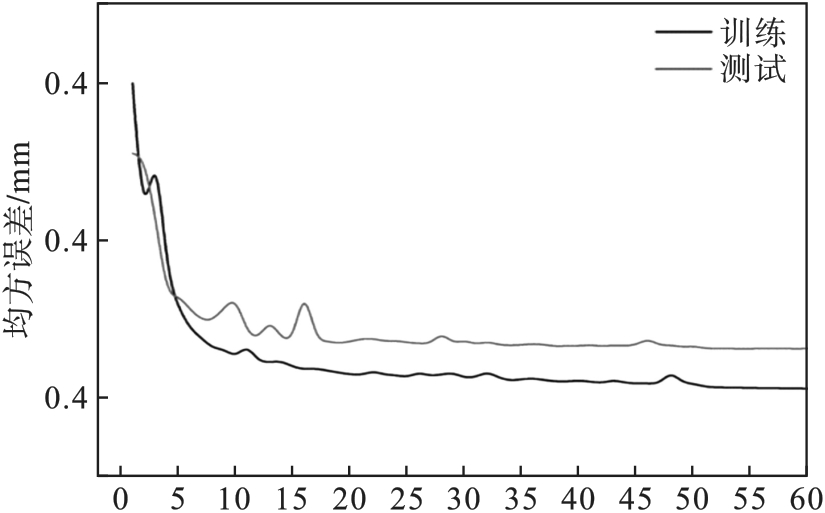
| [1] |
魏颖, 张家鹏, 崔佳琦, 黄通. 结合运动信息与双重注意力机制的两阶段SiamCAR跟踪算法[J]. 东北大学学报(自然科学版), 2025, 46(9): 9-16. |
| [2] |
李荟, 韩晓飞, 朱万成, 毛嘉石. 基于ICEEMDAN与Attention-LSTM的矿山边坡位移预测[J]. 东北大学学报(自然科学版), 2025, 46(7): 163-170. |
| [3] |
侯振隆, 申晋容, 魏继康, 赵文天. 基于SSD与图像变换的镜下矿物光片智能识别[J]. 东北大学学报(自然科学版), 2025, 46(6): 131-137. |
| [4] |
于滨, 孙红春, 叶大勇. 齿轮故障机理嵌入的变负载智能故障诊断[J]. 东北大学学报(自然科学版), 2025, 46(4): 61-70. |
| [5] |
沙晓鹏, 谢德瀚, 郭周鹏, 孙凯. LIDD-Net:基于深度学习的轻量级工业产品缺陷检测方法[J]. 东北大学学报(自然科学版), 2025, 46(10): 18-26. |
| [6] |
吕真真, 房立金, 赵乾坤, 万应才. 基于改进的YOLOv8的PCB瑕疵检测[J]. 东北大学学报(自然科学版), 2025, 46(10): 1-9. |
| [7] |
李海燕, 乔仁超, 李海江, 陈泉. 基于全局残差注意力和门控特征融合的CNN-Transformer去雾算法[J]. 东北大学学报(自然科学版), 2025, 46(1): 26-34. |
| [8] |
刘纪红, 黄熙雄. 基于去噪扩散概率模型的人脸图像修复模型[J]. 东北大学学报(自然科学版), 2024, 45(9): 1227-1234. |
| [9] |
刘炎, 卜齐杰, 赵红晨, 郭鑫. 基于多源异构信息的浮选过程运行状态评价[J]. 东北大学学报(自然科学版), 2024, 45(9): 1217-1226. |
| [10] |
田岸霖, 雷为民, 张鹏, 张伟. 一种基于编解码结构的多尺度边缘检测方法[J]. 东北大学学报(自然科学版), 2024, 45(7): 936-943. |
| [11] |
李红利, 刘浩雨, 张荣华, 成怡. 基于多维特征矩阵和改进稠密连接网络的情感分类[J]. 东北大学学报(自然科学版), 2024, 45(7): 928-935. |
| [12] |
刘纪红, 张律恒, 杨海旭. 一种细胞荧光显微图像饱和伪影修复算法[J]. 东北大学学报(自然科学版), 2024, 45(7): 921-927. |
| [13] |
刘伟嵬, 邱佳鹤, 胡光大, 刘泽远. 基于改进YOLOv5的退役轴类零件表面损伤检测方法[J]. 东北大学学报(自然科学版), 2024, 45(7): 1002-1010. |
| [14] |
马原, 佘黎煌, 李佳蔚, 鲍喜荣. 基于注意力机制的自适应图卷积三维点云识别算法[J]. 东北大学学报(自然科学版), 2024, 45(6): 786-792. |
| [15] |
韩东红, 孔彦茹, 展艺萌, 刘源. 音乐多模态数据情感识别方法的研究[J]. 东北大学学报(自然科学版), 2024, 45(6): 776-785. |