Journal of Northeastern University(Natural Science) ›› 2026, Vol. 47 ›› Issue (1): 75-81.DOI: 10.12068/j.issn.1005-3026.2026.20250040
• Information & Control • Previous Articles Next Articles
Chuang DONG1, Wei LI1,2( ), Cong BA1, Wen-jun TAN1,2
), Cong BA1, Wen-jun TAN1,2
Received:2025-04-22
Online:2026-01-15
Published:2026-03-17
Contact:
Wei LI
CLC Number:
Chuang DONG, Wei LI, Cong BA, Wen-jun TAN. Video-Text Retrieval Method Based on Cross-Modal Attention Mechanism[J]. Journal of Northeastern University(Natural Science), 2026, 47(1): 75-81.
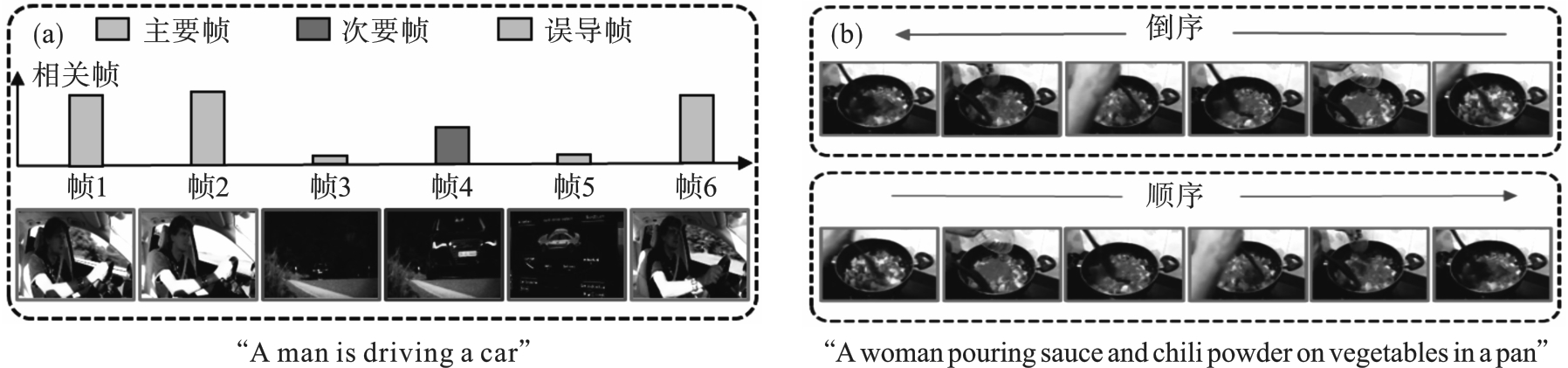
Fig.1 Impact of relevance information and temporal information during process of transferring image knowledge
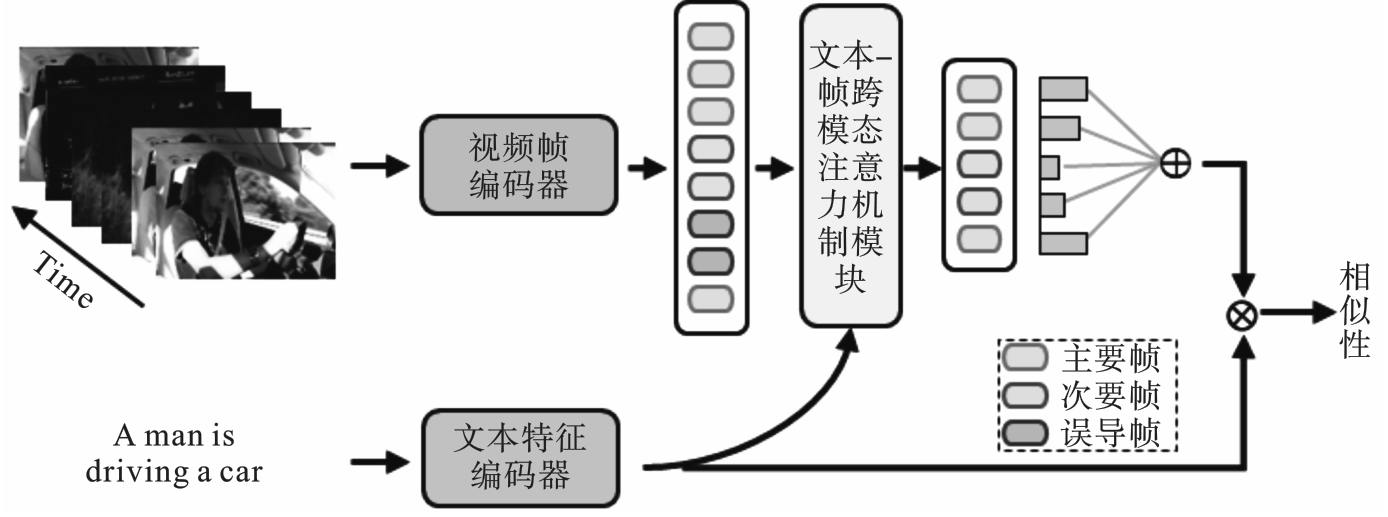
Fig.2 Architecture of video-text retrieval model based on cross-modal attention mechanism
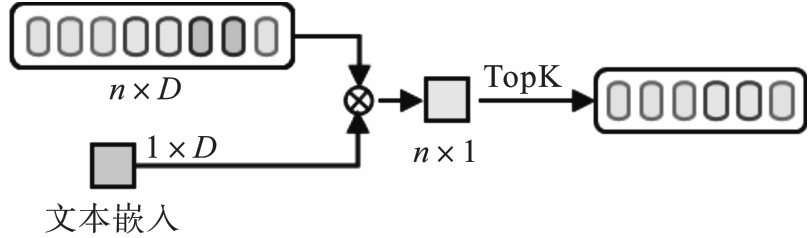
Fig.3 TopK text-frame cross-modal attention mechanism
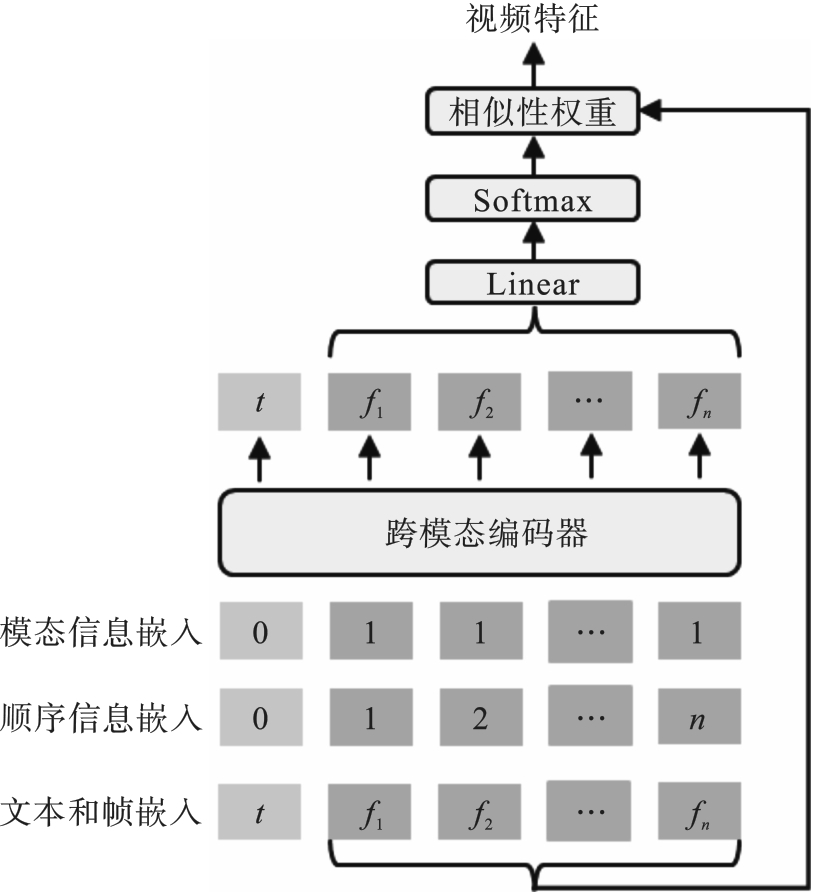
Fig.4 Joint text-frame cross-modal attention mechanism
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| ActBERT[ | 8.6 | 23.4 | 33.1 | 36.0 | — |
| Howto100M[ | 14.9 | 40.2 | 52.8 | 9.0 | — |
| ClipBERT[ | 22.0 | 46.8 | 59.9 | 6.0 | — |
| All-in-one[ | 34.4 | 65.4 | 75.8 | — | — |
| CLIP4Clip[ | 42.0 | 68.6 | 78.7 | 2.0 | 16.2 |
| X-Pool[ | 43.9 | 72.5 | 82.3 | 2.0 | 14.6 |
| Ours | 44.6 | 73.1 | 84.0 | 2.0 | 12.4 |
Table 1 Text-to-video retrieval results on
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| ActBERT[ | 8.6 | 23.4 | 33.1 | 36.0 | — |
| Howto100M[ | 14.9 | 40.2 | 52.8 | 9.0 | — |
| ClipBERT[ | 22.0 | 46.8 | 59.9 | 6.0 | — |
| All-in-one[ | 34.4 | 65.4 | 75.8 | — | — |
| CLIP4Clip[ | 42.0 | 68.6 | 78.7 | 2.0 | 16.2 |
| X-Pool[ | 43.9 | 72.5 | 82.3 | 2.0 | 14.6 |
| Ours | 44.6 | 73.1 | 84.0 | 2.0 | 12.4 |
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 26.6 | 57.1 | 69.6 | 4.0 | 24.0 |
| FROZEN[ | 32.5 | 61.5 | 71.2 | 3.0 | — |
| All-in-one[ | 37.9 | 68.1 | 77.1 | — | — |
| MAC[ | 38.9 | 63.1 | 73.9 | 3.0 | — |
| Clover[ | 40.5 | 69.8 | 79.4 | 2.0 | — |
| CLIP4Clip[ | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| RVTR[ | 45.8 | 73.0 | 83.5 | — | — |
| X-CLIP[ | 46.1 | 73.0 | 83.1 | 2.0 | 13.2 |
| X-Pool[ | 46.9 | 72.8 | 82.2 | 2.0 | 14.3 |
| STAN[ | 46.9 | 72.8 | 82.8 | 2.0 | — |
| DGL[ | 47.0 | 70.4 | 81.0 | — | 16.4 |
| TS2-Net[ | 47.0 | 74.5 | 83.8 | 2.0 | 13.0 |
| TABLE[ | 47.1 | 74.3 | 82.9 | 2.0 | 13.4 |
| Ours | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
Table 2 Text-to-video retrieval results on
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 26.6 | 57.1 | 69.6 | 4.0 | 24.0 |
| FROZEN[ | 32.5 | 61.5 | 71.2 | 3.0 | — |
| All-in-one[ | 37.9 | 68.1 | 77.1 | — | — |
| MAC[ | 38.9 | 63.1 | 73.9 | 3.0 | — |
| Clover[ | 40.5 | 69.8 | 79.4 | 2.0 | — |
| CLIP4Clip[ | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| RVTR[ | 45.8 | 73.0 | 83.5 | — | — |
| X-CLIP[ | 46.1 | 73.0 | 83.1 | 2.0 | 13.2 |
| X-Pool[ | 46.9 | 72.8 | 82.2 | 2.0 | 14.3 |
| STAN[ | 46.9 | 72.8 | 82.8 | 2.0 | — |
| DGL[ | 47.0 | 70.4 | 81.0 | — | 16.4 |
| TS2-Net[ | 47.0 | 74.5 | 83.8 | 2.0 | 13.0 |
| TABLE[ | 47.1 | 74.3 | 82.9 | 2.0 | 13.4 |
| Ours | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 12.9 | 29.9 | 40.1 | 19.3 | 75.0 |
| FROZEN[ | 15.0 | 30.8 | 39.8 | 20.0 | — |
| RVTR[ | 19.2 | 38.0 | 47.0 | — | — |
| DGL[ | 21.6 | 39.3 | 49.0 | — | 64.4 |
| CLIP4Clip[ | 22.6 | 41.0 | 49.1 | 11.0 | 61.0 |
| X-CLIP[ | 23.3 | 43.0 | 56.0 | — | — |
| TS2-Net[ | 23.4 | 42.3 | 50.9 | 9.0 | 56.9 |
| STAN[ | 23.7 | 42.7 | 51.8 | 9.0 | — |
| TABLE[ | 24.3 | 44.9 | 53.7 | 8.0 | 52.7 |
| Clover[ | 24.8 | 44.0 | 54.5 | 8.0 | — |
| X-Pool[ | 25.2 | 43.7 | 53.5 | 8.0 | 53.2 |
| Ours | 25.4 | 43.8 | 54.2 | 8.0 | 52.8 |
Table 3 Text-to-video retrieval results on LSMDC
| 模型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| MMT[ | 12.9 | 29.9 | 40.1 | 19.3 | 75.0 |
| FROZEN[ | 15.0 | 30.8 | 39.8 | 20.0 | — |
| RVTR[ | 19.2 | 38.0 | 47.0 | — | — |
| DGL[ | 21.6 | 39.3 | 49.0 | — | 64.4 |
| CLIP4Clip[ | 22.6 | 41.0 | 49.1 | 11.0 | 61.0 |
| X-CLIP[ | 23.3 | 43.0 | 56.0 | — | — |
| TS2-Net[ | 23.4 | 42.3 | 50.9 | 9.0 | 56.9 |
| STAN[ | 23.7 | 42.7 | 51.8 | 9.0 | — |
| TABLE[ | 24.3 | 44.9 | 53.7 | 8.0 | 52.7 |
| Clover[ | 24.8 | 44.0 | 54.5 | 8.0 | — |
| X-Pool[ | 25.2 | 43.7 | 53.5 | 8.0 | 53.2 |
| Ours | 25.4 | 43.8 | 54.2 | 8.0 | 52.8 |
| K | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 1 | 41.5 | 68.8 | 78.6 | 2.0 | 13.5 |
| 2 | 43.4 | 70.8 | 81.6 | 2.0 | 13.5 |
| 4 | 44.2 | 70.5 | 81.2 | 2.0 | 14.1 |
| 6 | 43.3 | 71.0 | 80.9 | 2.0 | 14.0 |
| 8 | 43.5 | 69.7 | 80.3 | 2.0 | 14.6 |
| 10 | 43.1 | 68.9 | 79.9 | 2.0 | 15.2 |
| 12 | 42.2 | 69.5 | 79.5 | 2.0 | 15.5 |
Table 4 Ablation experiment results of different K
| K | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 1 | 41.5 | 68.8 | 78.6 | 2.0 | 13.5 |
| 2 | 43.4 | 70.8 | 81.6 | 2.0 | 13.5 |
| 4 | 44.2 | 70.5 | 81.2 | 2.0 | 14.1 |
| 6 | 43.3 | 71.0 | 80.9 | 2.0 | 14.0 |
| 8 | 43.5 | 69.7 | 80.3 | 2.0 | 14.6 |
| 10 | 43.1 | 68.9 | 79.9 | 2.0 | 15.2 |
| 12 | 42.2 | 69.5 | 79.5 | 2.0 | 15.5 |
| 类型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 基准 | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| 无时间编码 | 46.8 | 72.5 | 82.4 | 2.0 | 14.2 |
| 有时间编码 | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
Table 5 Experimental results of temporal information
| 类型 | R@1 | R@5 | R@10 | MdR | MnR |
|---|---|---|---|---|---|
| 基准 | 44.5 | 71.4 | 81.6 | 2.0 | 15.3 |
| 无时间编码 | 46.8 | 72.5 | 82.4 | 2.0 | 14.2 |
| 有时间编码 | 47.2 | 73.1 | 84.3 | 2.0 | 11.3 |
| [1] | Radford A, Kim J W, Hallacy C, et al.Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning.Vienna: PMLR, 2021: 8748-8763. |
| [2] | Luo H S, Ji L, Zhong M, et al.CLIP4Clip: an empirical study of CLIP for end to end video clip retrieval and captioning[J].Neurocomputing, 2022, 508: 293-304. |
| [3] | Ma Y W, Xu G H, Sun X S, et al.X-CLIP: end-to-end multi-grained contrastive learning for video-text retrieval[C]// Proceedings of the 30th ACM International Conference on Multimedia.New York: Association for Computing Machinery, 2022: 638-647. |
| [4] | Wu W H, Luo H P, Fang B, et al.Cap4Video: what can auxiliary captions do for text-video retrieval?[C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver BC: IEEE, 2023: 10704-10713. |
| [5] | Fang H, Xiong P F, Xu L H, et al.Transferring image-CLIP to video-text retrieval via temporal relations[J].IEEE Transactions on Multimedia, 2023, 25: 7772-7785. |
| [6] | Bertasius G, Wang H, Torresani L.Is space-time attention all you need for video understanding? [C]//Proceedings of the 38th International Conference on Machine Learning.Vienna: PMLR, 2021: 813-824. |
| [7] | Liu R Y, Huang J J, Li G, et al.Revisiting temporal modeling for CLIP-based image-to-video knowledge transferring[C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver BC: IEEE, 2023: 6555-6564. |
| [8] | Xu J, Mei T, Yao T, et al.MSR-VTT: a large video description dataset for bridging video and language[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas: IEEE, 2016: 5288-5296. |
| [9] | Gorti S K, Vouitsis N, Ma J W, et al. X-Pool: cross-modal language-video attention for text-video retrieval[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans: IEEE, 2022: 5006-5015. |
| [10] | Miech A, Laptev I, Sivic J.Learning a text-video embedding from incomplete and heterogeneous data [EB/OL].(2018-04-07) [2024-10-24].. |
| [11] | Gabeur V, Sun C, Alahari K, et al. Multi-modal Transformer for video retrieval[C]// Computer Vision-ECCV 2020: 16th European Conference.Glasgow: Springer International Publishing, 2020: 214-229. |
| [12] | Liu Y, Albanie S, Nagrani A, et al.Use what you have: video retrieval using representations from collaborative experts [EB/OL].(2019-07-31) [2024-10-24].. |
| [13] | Jordan M I, Jacobs R A.Hierarchical mixtures of experts and the EM algorithm[J].Neural Computation, 1994, 6(2): 181-214. |
| [14] | Miech A, Zhukov D, Alayrac J B, et al.HowTo100M: learning a text-video embedding by watching hundred million narrated video clips[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Seoul: IEEE, 2019: 2630-2640. |
| [15] | Bain M, Nagrani A, Varol G, et al. Frozen in time: a joint video and image encoder for end-to-end retrieval[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Montreal: IEEE, 2021: 1728-1738. |
| [16] | Zhu L C, Yang Y.ActBERT: learning global-local video-text representations[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle: IEEE, 2020: 8743-8752. |
| [17] | Hochreiter S, Schmidhuber J. Long short-term memory[J].Neural Computation, 1997,9(8): 1735-1780. |
| [18] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach: Curran Associates Inc., 2017: 6000-6010. |
| [19] | Buch S, Eyzaguirre C, Gaidon A, et al.Revisiting the “Video” in video-language understanding[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 2907-2917. |
| [20] | Rohrbach A, Torabi A, Rohrbach M, et al.Movie description[J].International Journal of Computer Vision, 2017, 123(1): 94-120. |
| [21] | Kingma D P, Ba J.Adam: a method for stochastic optimization[EB/OL].(2017-01-30) [2024-10-24].. |
| [22] | Loshchilov I, Hutter F.SGDR: stochastic gradient descent with warm restarts[EB/OL].(2017-05-30) [2024-10-24].. |
| [23] | Zhao S, Zhu L C, Wang X H, et al.CenterCLIP: token clustering for efficient text-video retrieval[C]//Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval.Madrid: ACM, 2022: 970-981. |
| [24] | Wang J P, Ge Y X, Yan R, et al.All in one: exploring unified video-language pre-training[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Vancouver BC: IEEE, 2023: 6598-6608. |
| [25] | Shu F X, Chen B L, Liao Y, et al.MAC: masked contrastive pre-training for efficient video-text retrieval[J].IEEE Transactions on Multimedia, 2024, 26: 9962-9972. |
| [26] | Huang J J, Li Y N, Feng J S, et al.Clover: towards a unified video-language alignment and fusion model[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver BC: IEEE, 2023: 14856-14866. |
| [27] | Zhang H W, Yang Y, Qi F, et al.Robust video-text retrieval via noisy pair calibration[J]. IEEE Transactions on Multimedia, 2023, 25: 8632-8645. |
| [28] | Yang X, Zhu L, Wang X, et al. DGL: dynamic global-local prompt tuning for text-video retrieval[C]//Proceedings of the AAAI Conference on Artificial Intelligence.Vancouver: AAAI Press, 2024: 6540-6548. |
| [29] | Liu Y Q, Xiong P F, Xu L H, et al.TS2-net: token shift and selection transformer for text-video retrieval[C]// European Conference on Computer Vision.Cham: Springer, 2022: 319-335. |
| [30] | Chen Y Z, Wang J, Lin L J, et al.Tagging before alignment: integrating multi-modal tags for video-text retrieval[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Washington DC: AAAI Press, 2023: 396-404. |
| [1] | Xiao-tong LI, Xiao-long SONG, Jin-xin FAN, Zhao-xia WU. Prediction Model of BiGRU-Att Sinter Drum Index Based on Hybrid Feature Selection [J]. Journal of Northeastern University(Natural Science), 2026, 47(1): 107-114. |
| [2] | Ying WEI, Jia-peng ZHANG, Jia-qi CUI, Tong HUANG. Two-Stage SiamCAR Tracking Algorithm Combining Motion Information and Dual-attention Mechanism [J]. Journal of Northeastern University(Natural Science), 2025, 46(9): 9-16. |
| [3] | Hui LI, Xiao-fei HAN, Wan-cheng ZHU, Jia-shi MAO. Mine Slope Displacement Prediction Based on ICEEMDAN and Attention-LSTM [J]. Journal of Northeastern University(Natural Science), 2025, 46(7): 163-170. |
| [4] | Ji-hong LIU, Rui-rui SHI. An Improved Small Object Detection Model Based on YOLOv8 for UAV Vision [J]. Journal of Northeastern University(Natural Science), 2025, 46(12): 29-37. |
| [5] | Hui ZOU, Li-huang SHE, Ye-han CHEN, Yi YUE. 3D Gesture Estimation Algorithm Based on Geometric Attention Mechanism [J]. Journal of Northeastern University(Natural Science), 2025, 46(10): 44-50. |
| [6] | Xiao-peng SHA, De-han XIE, Zhou-peng GUO, Kai SUN. LIDD-Net: Lightweight Industrial Product Defect Detection Method Based on Deep Learning [J]. Journal of Northeastern University(Natural Science), 2025, 46(10): 18-26. |
| [7] | Zhen-zhen LYU, Li-jin FANG, Qian-kun ZHAO, Ying-cai WAN. Defect Detection on PCB Based on Improved YOLOv8 [J]. Journal of Northeastern University(Natural Science), 2025, 46(10): 1-9. |
| [8] | Hai-yan LI, Ren-chao QIAO, Hai-jiang LI, Quan CHEN. CNN-Transformer Dehazing Algorithm Based on Global Residual Attention and Gated Feature Fusion [J]. Journal of Northeastern University(Natural Science), 2025, 46(1): 26-34. |
| [9] | Yan LIU, Qi-jie BU, Hong-chen ZHAO, Xin GUO. Operating Performance Assessment of Flotation Process Based on Multi-source Heterogeneous Information [J]. Journal of Northeastern University(Natural Science), 2024, 45(9): 1217-1226. |
| [10] | An-lin TIAN, Wei-min LEI, Peng ZHANG, Wei ZHANG. A Multi-scale Edge Detection Method Based on Encoder-Decoder [J]. Journal of Northeastern University(Natural Science), 2024, 45(7): 936-943. |
| [11] | Wei-wei LIU, Jia-he QIU, Guang-da HU, Ze-yuan LIU. Surface Damage Detection Method for Retired Shaft Parts Based on Improved YOLOv5 [J]. Journal of Northeastern University(Natural Science), 2024, 45(7): 1002-1010. |
| [12] | Yuan MA, Li-huang SHE, Jia-wei LI, Xi-rong BAO. Adaptive Graph Convolutional 3D Point Cloud Recognition Algorithm Based on Attention Mechanism [J]. Journal of Northeastern University(Natural Science), 2024, 45(6): 786-792. |
| [13] | Li-xin GUO, Su-tao BI, Ming-yang ZHAO. State Detection Algorithm of Manipulator Based on Improved YOLOv4 Lightweight Network [J]. Journal of Northeastern University(Natural Science), 2024, 45(6): 769-775. |
| [14] | Hu FENG, Ke-chen SONG, Wen-qi CUI, Yun-hui YAN. Few-Shot Semantic Segmentation of Strip Steel Surface Defects Based on Meta-Learning [J]. Journal of Northeastern University(Natural Science), 2024, 45(3): 354-360. |
| [15] | Bo HAO, Xin-yan XU, Yu-xin ZHAO, Jun-wei YAN. Surface Defect Detection of Riveting Holes Based on Improved YOLOv8 [J]. Journal of Northeastern University(Natural Science), 2024, 45(11): 1595-1603. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||